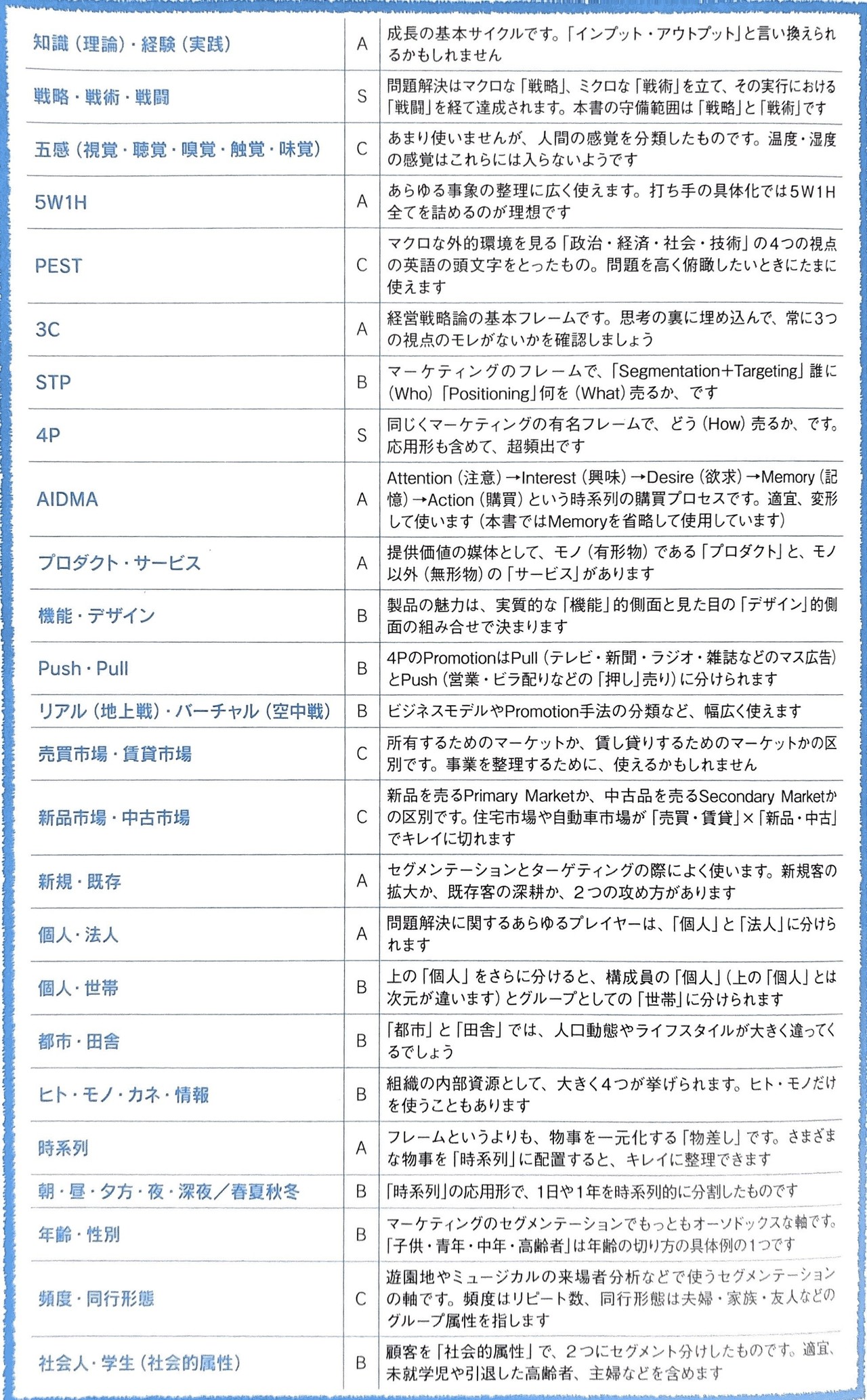
「考える技術・書く技術」
【追補A 前半】
追補Aでは、論理的推論(論理的思考に近いが、同義ではない)についての説明をいたします。
まず、当該書籍では「理由づけ」という言葉が散見されますね。
本書の中で「理由づけ」という言葉が出てくる箇所を探してみると、追補Aの「分析的問題解決における不明推測法」の節に「すべての理由づけのプロセスにおいては、3つの基本要素を相手にする」と書いてあり、第1部第5章に「演繹的理由づけ」「帰納的理由づけ」の節があります。
しかし、これは訳し方が変ですよね。この理由づけという言葉を「推論」という言葉に置き換えると、意味が通りますね。
「すべての推論のプロセスにおいては、3つの基本要素を相手にする」「演繹的推論」「帰納的推論」になります。
文脈から考えると、この「理由づけ」という言葉はおそらく"reasoning"を訳したものものだと思われます(洋書の方を確認していないので単なる憶測ですが)。
reasoningの適訳は「推論」であり、このように解釈すると本書の内容が理解できるのではないでしょうか。
では、「理由づけ」ではなく「論理的推論」の説明をして行きます。
●論理的推論とは何か
論理的推論とは、文字通り論理的に推論することですが、それでは「論理的」や「推論」はどのような意味なのでしょうか。
「推論」とは、既知の情報や与えられた情報をもとにして未知の情報を導くことです。
そして、次の3つの要素を含むものが「論理的な」推論と言えます。
①ルール(規則):
・世の中のものが形作られるその方法についての考え
ex)売上を形作る要素は販売数量と価格である、価格を高く設定すれば販売数量が減って売上が低下する
・普遍的に成り立つ性質
ex)長方形の面積は縦の辺の長さ×横の辺の長さで求められる、F=ma、PV=nRTなど
・傾向として一般的に成り立つ性質
ex)人間は死ぬ(不老不死の人間が将来的に誕生する可能性を考慮してあえて一般的に成り立つ性質に分類した)、雨が降ると芝生は濡れる、独占禁止法の目的は生産と流通の活性化である、次の3つの条件を満たす企業は全て買収に値する、4つのことをうまく行うと生産数量が増大する
などのこと。
ざっくり言えば、ルールは「抽象」のこと。
追補Aには、「世の中のものが形作られるその方法についての考え」とだけ書かれているが、少々分かりにくいので3つに分けた。
②ケース(事例):世の中に存在し、観察される個々の具体的な事物や事例、事実などを指す。
私、彼、ポチ、x^2+2x+1=0の解を求めよ、円周率が3.05より大きいことを証明せよ、A社が価格を高く設定した、Apple社の売上が低迷しているので解決して欲しい、北朝鮮が核ミサイルを発射する恐れがあるので解決すべきだなど。
ざっくり言えば、ケースは「具体」のこと。
③結果:ケースにルールを適用した場合に予測される出来事。
有名な例としてはソクラテスの三段論法が挙げられる。「全ての人間は死ぬ(ルール)。ソクラテスは人間である(ケース)。ゆえに、ソクラテスは死ぬ(結果)」という論法。他の例を挙げると、ルールが「長方形の面積をS、縦の辺の長さをa、横の辺の長さをbとすると、S=a×b」だとして、ケースが「a=4、b=3」だとすると、出力される結果は「S=12」となる。
論理的推論に含まれる要素は以上3点です。
そして、これら3つの要素を含みつつ既知の情報から未知の情報を推論する行為のことを論理的推論と定義します。
ちなみに、論理的推論は論理的思考とは異なります。論理的推論は既知の情報に基づいて未知の情報を推知することですが、論理的思考は必ずしも推論とは限りません。例えば、類推はA≒Bという式で表すことができるので論理的ではありますが、未知の情報を推論するわけではないので論理的推論とは言えません。論理的推論のパターンはあくまで以下の三種類です。
①演繹法(deduction):ルール→ケース→結果
②帰納法(induction):ケース→結果→ルール
③仮説法(abduction):結果→ルール→ケース
論理的推論にはこれら3パターンしかありません。
逆に言えば、どのような問題を相手にするにせよ、問題を解決するにはこれら3つの思考法のうちのどれかしか用いないということです。
それぞれの違いは、ルールとケースと結果を巡る順序です。下図をご覧ください。どこから出発するかによって思考法が変わります。ルールから出発して時計周りで周回すれば演繹法。ケースから出発すれば帰納法。結果から出発すれば仮説法になります。つまり、与えられた情報や既知の情報が何かによって、取るべき推論パターンが変化します。
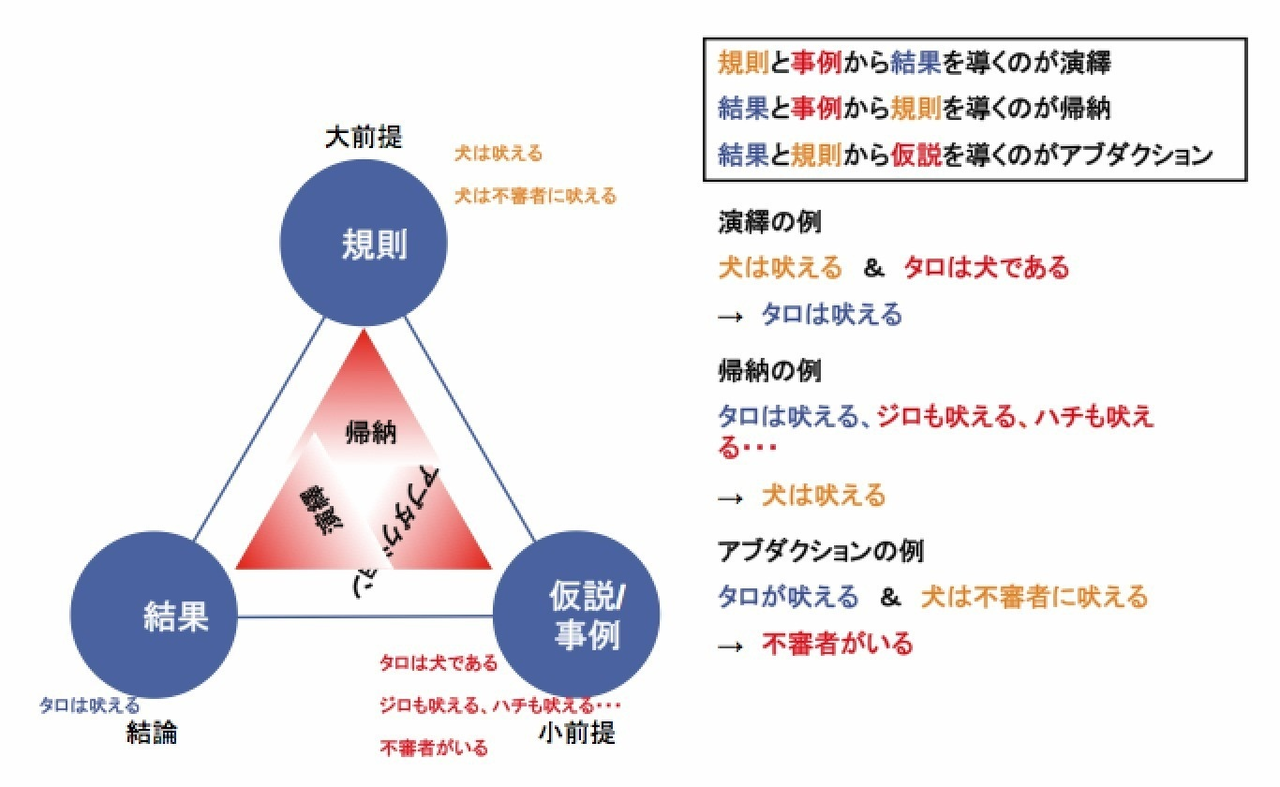
では、それぞれについて詳しく見ていきましょう。
●演繹法(deduction)
▪️どのような性質か
演繹法は、2つの前提(ルールとケース)から結論を導く論証形式です。ざっくり言えば、抽象的な情報を個々の具体的な事例に当てはめて結論を導く考え方です。
この時、ケースはルールの主語か述語のどちらかに対して言及している必要があります。先ほど挙げたソクラテスの例や四角形の面積Sを求める手続きが演繹法に該当しますが、
ソクラテスの例では「全ての人間は死ぬ(ルール)。ソクラテスは人間である(ケース)」となっていて、ルールの主語がケースの述語になっていますね。つまり、共有する単語が存在するということです。
さらに、四角形の面積Sを求める手続きにおいては、ルールとケースの間で縦の辺の長さaと横の辺の長さbを共有しています。
以上が演繹法の基本的な性質ですが、これだけでは使い方が分からないと思うので、使い方を説明しましょう。
▪️どのように使うか
演繹法は主に数学者が用いる推論パターンです。
まず、中学や高校レベルの数学・理科の問題を解く際は、どのような問題であれ演繹法に従います。ルール(定理や公式、定義など)をケース(個々の具体的な問題)に当てはめて答えを導くので。
しかし、演繹法は理系科目の専売特許ではありません。日常生活やビジネスの諸問題でも適用されます。いわゆる「原理原則」がルールに当てはまります。古典に書かれているような原理原則を各事例に適用して結論を導くことは、演繹的な推論と言えます。
演繹法を使うためには、ルールを知っておく必要があります。数学や理科で言えば定義や定理。ビジネスで言えば、原理原則と言われるもの。
演繹法の利点としては、ルールになるようなものは基本的に数が少ないので、演繹的推論ができると膨大な暗記をする必要が無くなるってことですね。一方、解法暗記(類推)による解決の仕方では、膨大な暗記が必要になるので、大変な労力を伴います。
●帰納法(induction)
▪️どのような性質か
帰納法は、いくつかの事例や事実を集めてその共通点を見出し、共通する一般的な性質を導く方法です。
例をあげると、「カラスa1は黒い。カラスa2も黒い、カラスa3も黒い。よって、全てのカラスは黒い」と一般化するものが帰納法にあたりますね。
他の例としては、「成功法則」などが挙げられます。成功者を観察した結果、いくつかの共通点が見つかったので一般化してまとめ上げたもののことです。
▪️どのように使うか
帰納法は主に科学者が用いる推論パターンです。
帰納法の注意点としては、帰納法はあくまで蓋然的に(確率的に)正しいとされる推論に過ぎないということです。
カラスが過去・現在・未来の全ての時系列や全ての場所において黒い保証はありません。遺伝子の変異による白いカラスが発見されるかもしれないので。
さらに、成功法則も100%成立するものではないですね。あくまで確率的に高いかどうかの話に過ぎません。
●仮説法(abduction)
▪️どのような性質か
これは仮説思考のことです。通称はアブダクション。
ある出来事(結果)を見たときに、それに対して仮説を立てる考え方で、例えば、「今朝見たら芝生が濡れている(結果)→雨が降ると芝生が濡れる(ルール)→昨夜雨が降ったのかもしれない(ケース)」と推論するのがアブダクション的な考え方ですね。
アブダクションは仮説思考のことですが、時にルールは暗黙知になります。たとえば、普通の人間であれば「今朝見たら芝生が濡れている(結果)→通常、雨が降ると芝生が濡れる(ルール)→昨夜芝生が降ったのだろう(ケース)」といった推論をせず、「芝生が濡れてるから昨夜雨が降ったのだろう」といったように、ルールを無意識のうちに省略して推論します。
しかし、このような無意識の処理は複雑な問題であれば困難になります。経験を積んでない人なら、丁寧に要因分析や解決策立案をする必要がありますね。
ただ一方で、相当な経験を積んで仮説思考に慣れている人であれば、ちらっと現場を眺めたり現象を観察するだけで、即座に要因と解決策が導けるでしょう。
論理的というよりはむしろ直観的ではありますが、問題解決の要となる考え方であり、「考える技術・書く技術」の第3部では、アブダクションによる問題解決手法を提示しています。
▪️どのように使うか
アブダクションは主に臨床医や探偵、ビジネスマンが使う推論パターンです。臨床医は患者の症状を聞き、それに対して「これが原因なのではないか?」という原因の仮説を立てて、詳細情報を患者に質問しますよね。
このように、起きた結果(=症状)から直観的に仮説を立てるのがアブダクションです。この考え方は最も身近なものかもしれません。
論証力は弱いですが、直観的なので思考スピードは速いです。ビジネスのようにスピードが重視される世界では重宝される考え方ですね。

【第8章 問題を定義する】
前述した三種類の論理的推論を押さえた上で、問題解決の体系的な技法を学びます。それが連鎖分析プロセスです。
連鎖分析プロセスは次の5つのステップを踏みます。
フェーズ1:問題はありそうか?(問題があるかどうかの確認を行う)
フェーズ2:問題はどこにあるか?(問題が発生した状況を簡潔に述べる。どこで問題が発生したか)
フェーズ3:問題はなぜ存在するのか?(フェーズ2に基づいて、より詳しい要因分析を行う)
フェーズ4:問題に対し何ができるか?(問題に対する解決策を複数リストアップする)
フェーズ5:問題に対し何をすべきか?(解決策を絞り込んで1つに定める)
大きな流れで言えば、問題があるかどうかの確認(フェーズ1)→要因を分解して真因を特定(=論点設定。フェーズ2と3)→解決案立案(フェーズ4と5)という流れになります。勘の良い方は気づいたかもしれませんが、これはアブダクションの考え方と言えます。フェーズ1が結果に該当し、フェーズ2と3がルール(要因の構造化)に該当し、フェーズ4と5がケース(解決策)に該当します。問題解決における推論パターンは演繹法と帰納法とアブダクションの三種類ありますが、ビジネスの問題を解決する場合はアブダクションを使用する場合が多いです。スピードが非常に速いので。
ところで、問題と直面した時にいきなり解決策を立案する人がいますが、あれは一部の簡単な問題にしか使えない方法です。多くの問題では、問題を引き起こした要因を分析して、真因(=論点)に対してピンポイントで解決策を与える必要があります。
お医者さんはまさにその方法で臨床を行ってますよね。例えば、「お腹が痛い」という理由でお医者さんに診断してもらうと、場当たり的に解決策を提示するのではなく、「いつからお腹が痛いのか」「慢性的に痛いのか」「具体的にどのような症状が出ているのか」「何か薬は飲んでいるか」「何か持病はあるか」「両親もお腹が弱いのか」などの質問を通して原因を探ってきます。質問で原因が判明しなかった場合、CTや胃カメラで原因を探ります。そして、原因が分かり次第、それに対してピンポイントで解決策(薬など)を与えます。
以上の例からも分かるように、まずは問題を引き起こしている犯人を突き止めることが大切です。
また、要因分析のフェーズであれ解決策提示のフェーズであれ、思考が行き詰まって前進できないことがあります。みなさんも経験ありますよね。「何をどう考えれば良いのか分からない」となることが。こういう場合も、「なぜ思考が行き詰まっているのか?」と考えることで、前進できることがあります。つまり、思考の阻害要因を突き止めるってことです。
加えて、これから解説する問題解決の体系的な技法を身につけることによってどのようなレベルになるかイメージを掴んでもらうため、以下のリンクを参照して下さい。
http://kaz-ataka.hatenablog.com/entry/20081018/1224287687
では、それぞれのフェーズを詳しく見ていきましょう。第8章では、フェーズ1と2を扱っています。
●フェーズ1 問題はありそうか?
そもそも問題とは何でしょうか?まずは用語の定義からしましょう。RはResultの頭文字です。
R1:望ましくない結果(多くの場合、現状を指す)。1つしかない場合もあれば複数存在する場合もあるが、いずれも簡潔に述べるようにする。
R2:望ましい結果(=理想や目標)。成果を計測できるように、具体的な表現や定量化された表現にすること。必ずしも定量化する必要はないが、必ず計測可能な表現にすること。もし具体的に表現できない場合は、R2を具体的に表現することが問題解決の第一ステップとなる。R2を定量化するコツは以下の通り(以下の方法は本に記載されていない)。
①目標を「金額」によって数値化する
ex)売上○億円達成、営業利益○億円達成、年収○○万円達成など。
②目標を「回数」によって数値化する
ex)クレームを月○回に抑える、お客様を一日に○回笑顔にする、筋トレやランニングを週に○回行うなど。
③目標を「率」によって数値化する
ex)売上を前年比120%にする、コストを30%削減する、市場シェアを30%から50%にするなど。
④目標を「時間」によって数値化する
ex)ある作業を○時間でやる、売上○万円を△月までに達成するなど。
⑤目標を「点数・ポイント」によって数値化する
ex)10段階評価で7を達成、自己評価・他者評価でおおよそ80点を達成など。
⑥目標を定量化可能になるまで分解する
ex)「仕事ができるようになりたい」という目標に対して「そもそも仕事ができる人って何だろう」と問いを投げかけ、仕事ができる人の要素を分解していく。例えば、問題解決能力であったり、コミュニケーション能力であったっり、行動力である。しかし、これではまだ定量化が難しいので、定量化しやすくなるまで分解を続けていく。
問題(problems):R2-R1のこと。言い換えると、R2-R1(=理想ー現状)のギャップを生み出す要因やR2-R1の間にある障壁のこと。
理想と現状を隔てる要因は複数存在するので、当然問題も複数存在することになる。
なお、本には書いていないことだが、R1そのものは問題ではない。あくまでファクト(=現象や観察事実)に過ぎない。R1を引き起こし、R2に到達する妨げをしている要因が問題と言える。例えば、「お腹が痛い」は問題ではなくR1そのものである。問題となるのは、腹痛(=R1)を引き起こしている種々の要因(ストレス、血圧、薬の副作用、生活習慣の乱れなど)である。これらの要因がR1を引き起こし、そしてR2とR1のギャップを作り、R2(=腹痛がない状態)に到達する妨げをしている。
論点(real problem):これも本には書いていないことだが、その複数存在する問題(=要因)の中で、真に解くべき問題(=解決策を与えるべき問題)のこと。真因とも言える。つまり、解決すればR1からR2に向かって大きく前進できると考えられるもの。多くの場合、時間やお金などのリソースが限られているため、全ての問題に対処していてはキリがない。解決しても大して効果が上がらない問題もあれば、解決することで大きく前進できる問題もある。そこで、複数の論点候補(=問題=要因)の中から問題解決に直結しそうな問題を1つ、多くても2つ選び出し、それに対して解決策を与えて実行するようにする。
論点設定は、いわゆる要領の良さに関わるもの。要領が悪い人は行動にメリハリがなく、あれもこれも手をつけたがる傾向にある。一方、要領が良い人は、しっかりと成果を出せるツボを押さえて短時間かつ低労力で効率的に問題を解決する。何をやるにしてもこの論点設定は非常に重要で、これができるかどうかでProblem Solverとしての質が決定されると言っても過言ではない。
ちなみに、混同されがちな言葉として課題(issue)という言葉があるが、problemが解決すべき問題を表すのに対して、issueは賛成する人がいたり反対する人がいたりする賛否両論の論題を表す。つまり、Yes/Noに分かれる論題のこと。
したがって、「どのように機能を再構築すべきか?」はproblemにはなるが、issueにはならない。「機能を再構築すべきか?」はissueになる。
問題発見:論点を見つけること。フェーズ1で行われる問題(R2-R1)があるかどうかの確認は、問題発見ではない。
問題解決:R1からR2に移動すること。つまり、問題に対して解決策を与えて実行し、障壁を取り払ってR2に到達すること。R2に到達しなければ問題が解決されたとは言えない。R2に到達して初めて解決したことになる。基本的には、問題解決は疑問とそれに対する答えがセットになっている。つまり、どうしたら良いのか?なぜなのか?どちらが良いのか?これは正しいのか?といった種々の疑問に対して答えを与える作業が問題解決である。わかりやすく言えば、Q&A。したがって、効率的に問題解決を行うコツは、適切な問いを設定することにあり、そのための作業がフェーズ1~3で行うこと。フェーズ4~5で行うことは問いに対する答えを導くこと。そして、出力された答えを実行してR2に到達して初めて問題が解決されたことになる。
用語の定義は以上になります。このフェーズでは、問題、つまりR2-R1があるかどうかを確認するだけなので多くのことを学ぶ必要はありませんが、
これだけでは分かりにくいかと思いますので、具体例をいくつか並べましょう。
具体例①:大学受験生のケース
R2を東大文科二類合格、R1を駿台の東大実戦で総合偏差値40としましょう。この時、受験生が目標としているのはR1からR2に移動することです。このR1とR2のギャップが存在していることを確認するのが、フェーズ1で行うことです(このケースでは、R1とR2のギャップが存在しているので、フェーズ1は完了しました)。
そして、R1(=東大実戦で総合偏差値40)を生み出している要因は複数存在します。勉強時間が少ない、集中できない、どの問題集を買ったら良いのか分からない、問題集をどのように進めれば良いのか分からない、勉強の進め方は分かっているつもりだが正しいのかどうか分からない、理解力が低い、記述が苦手、処理能力が低い、時間が足りない、出題傾向を把握していない、などです。
これらが問題(=論点候補)に当たりますが、この情報だけでは何が論点(=解決することで大きく前進できる問題)か分かりませんね。したがって、フェーズ2や3を通して、論点を見つけ出します。
具体例②:就活生のケース
R2を外資系投資銀行や外資系戦略コンサルティングファームや五大商社内定としましょう。そして、R1(=現状)をよく理解していないと仮定しましょう。つまり、このケースは「自己分析ができていないがとりあえずエリートになりたい就活生」のケースです。
この時、R1とR2のギャップを生み出す要因は何でしょうか。面接で何を聞かれるか分からない、面接で何を言えば良いのか分からない、誰に相談して良いか分からない、OB訪問は何人すれば良いのか分からない、ESをどうやって書けば良いのか分からない、Webテの対策ができていない、そもそもR1(=自己分析)が曖昧、などがあります。書き出そうと思えば無限と思える程の量がリストアップされるでしょう。
フェーズ1ではR1とR2のギャップがあるかどうかを確認するだけですが、このケースではR1を明確にすることから始めます。こうすることで、理想と現状の差が明確になるので何をすべきかが分かり、論点を絞り込めるようになります。R1とR2が曖昧模糊なままでは何が真因か分からず、行動が先走ってあれもこれも手をつけてしまう羽目になるでしょう。
具体例③:オリンピックの金メダル獲得数を増やす方針を考えるケース
ケース面接ではこのようにR1とR2が曖昧な問題が出題されますが、こういう場合はR1とR2を仮説的に設定します。そして、さらに重要なこととして、R2(=オリンピックの金メダル獲得数を増やすこと)が本当にゴールとして適切なのかを検討する必要があります。つまり、なぜ金メダル獲得数を増やしたいのかということです。国の威信を上げたいのかもしれませんし、国民にもっとスポーツに関心を持ってもらいたいのかもしれません。となると、金メダル獲得数を増やすことは上位目的に対する手段でしかないわけですね。もしかしたら金メダル獲得数を増やすよりも、他に有効な手段があるかもしれません。
このように、R2が本当に正しいのか、なぜR2を目標とするのかを批判的に検討する必要があります。目的と手段を区別することで、解決する必要のない問題を避けて通ることができます。
具体例は以上となりますが、ここで、R2-R1の存在を確認する上でのステップを整理しておきましょう。
ステップ1:R1とR2が存在するかを確認する
ステップ2:存在するとして、なぜR2を目標とするのか、そもそもR2は本当に望むべきことなのか批判的に検討する。つまり、目的と手段を区別する。そして、R1が正しい情報なのか、バイアスがかかっていないかを検討する。
ステップ3:最後に、R1とR2は明確になっているかを確認する。もし明確になっていなければ、明確にすることから始める。ただし、R1は簡潔に記述すること。
フェーズ1で必要となる要素はR1とR2だけですから、このようなステップが発生することは当然と言えます。
また、なぜこのような順序になるかと言うと、問題解決がR1からR2に移動することだからです。そのためには、R1とR2のそれぞれが本当に正しいのかを批判的に検討して、その上で明確にする必要がありますよね。これによって無駄な作業を減らすことができます。
人間はバイアスがかかっていますから、R1を正確に把握できていなかったり(過大評価や過小評価など)、現実から目を背けてしまうことがあります。さらに、R2を計測可能な形で明文化できていないケースもよくあります。例えば、「仕事ができるようになりたいけど、イメージが曖昧としていてどこに向かったら良いのか分からない」というケースです。このようなケースは頻繁に見られますが、まずはR2を明確にすることから始めましょう。
もちろん、必ずしもこの方法や順序に従う必要はありません。あくまで便宜的な順序です。ハウツーに忠実な人は全ての目標を定量化したがると思いますが、僕は毎回そんなことをしてるわけじゃないです。流動的に(=臨機応変に)思考を働かせるのが良くて、スピード重視で問題解決することを意識しています。
ちなみに、「考える技術・書く技術」を読むとステップ2は明示的には書かれていません。しかし、p184に「R1,R2の定義は問題解決を進めていく上で何度かの修正を伴うのが普通です」と書いてあります。したがって、R1とR2を批判的に検討すること自体は本の内容と合致しています。基本的にはスピード重視ですから、R1とR2を暫定的に決めておき、あとで修正すれば良いやという態度で前進するのも有効です。定量化や明確化に足を引っ張られていては元も子もないですから。
●フェーズ2 問題はどこにあるか?
フェーズ2では、R1を引き起こした状況に遡ります。つまり、問題を引き起こしている要因を簡潔に記述することがこのフェーズでの目的になります。
まずは用語の定義をしましょう。
状況:スタートポイント+懸念される出来事
スタートポイント/オープニング:問題が発生する時間的・空間的状況。スタートポイント/オープニングには構造とプロセスの2つしかない。
懸念される出来事:スタートポイント/オープニング(構造かプロセス)で発生し、R1の引き金になるもの。懸念される出来事は、大きく分けて外的要因か内的要因か新しい認識のどれかになる。
外的要因:構造/プロセスを取り囲む環境から引き起こされる変化。例えば、新たな競合の出現や新たな技術への転換、政府方針や顧客の変化など。
内的要因:当事者自身により引き起こされる変化。例えば、ビジネスプロセスを増やした、新たなコンピューターシステムを導入した、新たな市場へ進出した、製品ラインを変更した、など。
新たな認識:変化が必要なことへの新たな認識。例えば、製品やプロセスの能力低下、水準以下の結果、顧客変化を意味する市場リサーチなど。
これだけでは分かりにくいかと思うので、いくつか具体例を並べましょう。具体例①②が構造に起因したR1で、具体例③④がプロセスに起因したR1です。
具体例①:パソコンが故障した
ある時、手持ちのパソコンが故障してしまいました(=R1)。あなたはその原因を探り、解決しようとしています。この時、R1を引き起こした原因はPCの構造、つまり、ハードウェアやソフトウェアなどのどこかにあるはずです。
このコンピューターの構造こそがまさにスタートポイントであり、この構造(=スタートポイント/オープニング)のどこかにR1の引き金となったバグ(=懸念される出来事)が存在しています。懸念される出来事は常にスタートポイント/オープニングの中に存在しています。
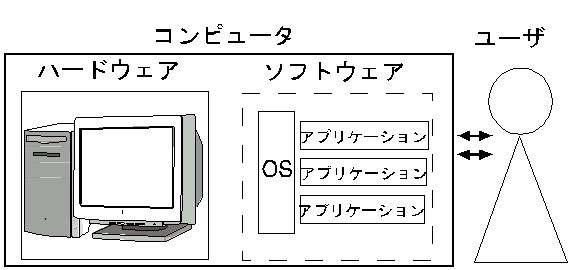
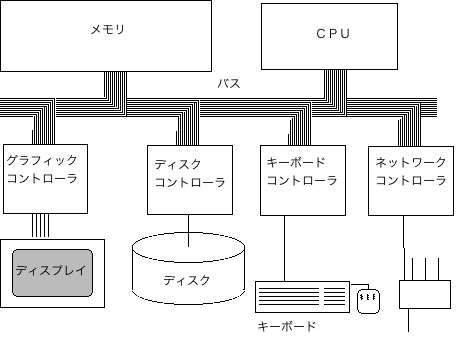
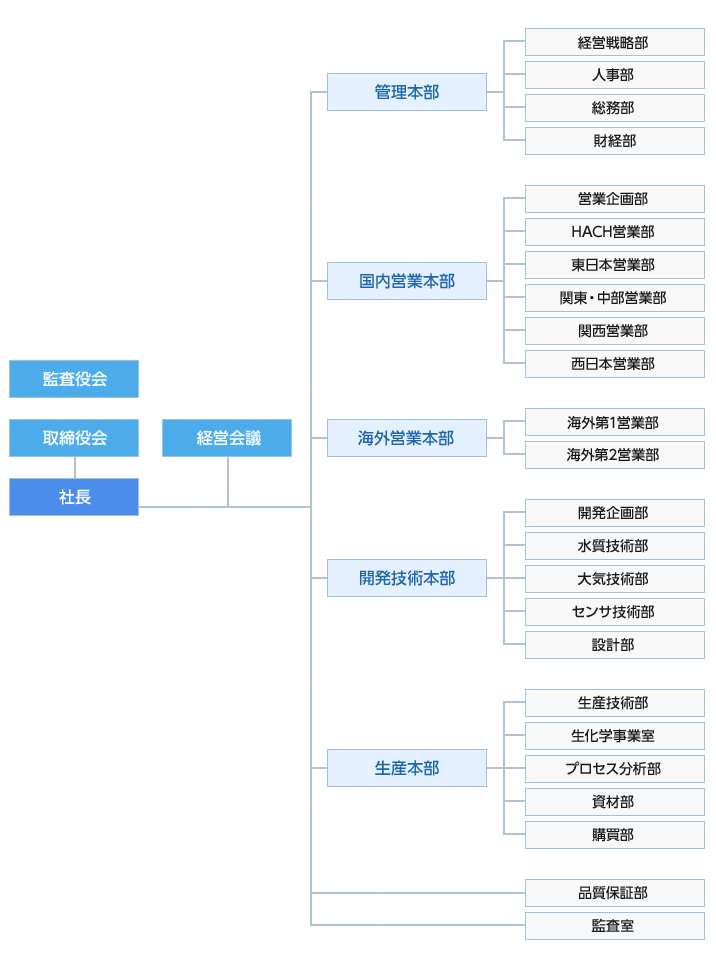
具体例②:会社で問題が発生した
会社組織における問題の原因には様々なものがありますが、各組織を分解することでどこに問題があるのか特定できることがあります。まずは下図をご覧ください。会社の成長が妨げられている要因が各組織の中のどこかにある場合、この構造(=スタートポイント/オープニング)の中のどこかにバグ(=懸念される出来事)が存在し、それがR1を引き起こしていると考えられます。R1は何らかの状況(=スタートポイント+懸念される出来事)によって生じていることがわかるでしょう。
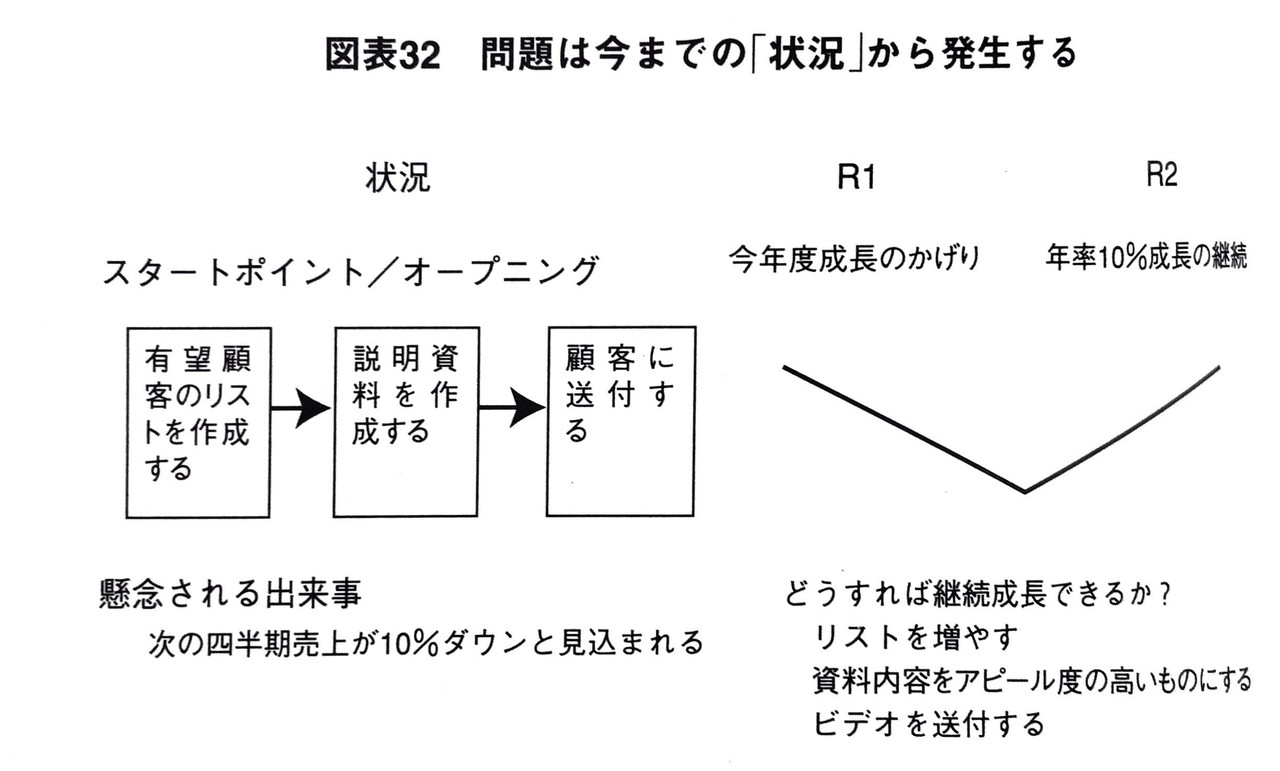
具体例③:今年度成長のかげり
あなたはある会社のオーナーであり、 30年間同じようなやり方で大きな需要に恵まれた商品を売っていたとします。例えば、産業用の不動産としましょう。セールスマンは単に有望顧客のリストを作り、説明資料を作成し、それを顧客に送付するだけです。 会社は異常と思えるほど良い業績を続け、 毎年10%以上も売り上げを伸ばしてきました。 ところが、今年の第4四半期に入ると、 どうもこの期は10%どころではなく10%ダウンの様相を呈しています。当然、会社にとってこのニュースは大きなショックであり、ともかく販売を元の成長軌道に戻すために、大至急可能な処置をとりたいと考えます。
図にすると下のようになります。
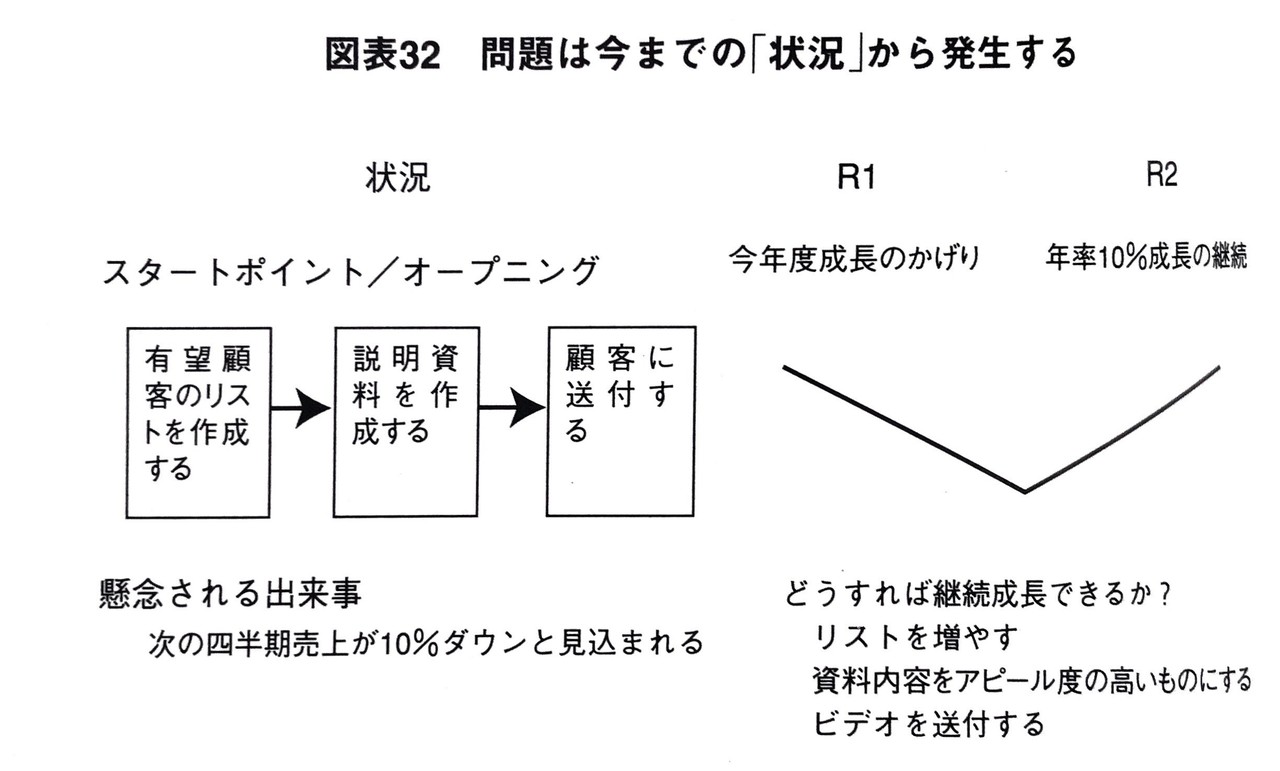
この図におけるプロセス(=スタートポイント/オープンニング)によって会社はこれまで望ましい結果を得ていたのに、突然問題が発生してしまいました。
このケースでは、R1の引き金となったバグ(=懸念される出来事)がこのプロセスの中に存在している可能性があります。つまり、スタートポイント/オープニングの3つのステップのどこかにバグが存在し、それがR1を引き起こしているということです。
ちなみに、図をみると懸念される出来事が「次の四半期売上が10%ダウンと見込まれる」と書いてありますが、これは「新たな認識」のことですね。つまり、スタートポイント/オープニングの中で、何かが起こった、あるいは、何らかの行動が取られて(販売予測を試算した)、新たな認識が発生したということです。そして、その認識がR1を引き起こした(というより、R1があることに気づいた)と言えます。
スタートポイント/オープニングの中に存在するバグと表現すると語弊があるかもしれませんが、「懸念される出来事」は定義上R1を引き起こすものですから、新たな認識であろうが何であろうがバグであることには変わりません。
具体例④:勉強しても学力が上がらない
何かの試験を控えている受験生が行うことは、問題集を買ってきて勉強することです。これをプロセスの形式で図式化してみましょう。
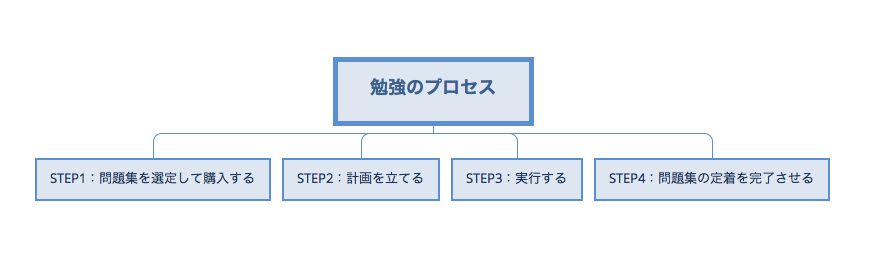
このプロセスがまさにスタートポイント/オープニングであり、もし成績が思うように上がらない場合、このステップのどこかに原因がある可能性があります。購入する問題集が試験に対して不適切だったり不要なものなのかもしれませんし、計画を立てるのが下手なのかもしれませんし、計画を実行できないのかもしれません。あるいはそれら全てかもしれません。いずれにせよ、スタートポイントのどこかにバグ(=懸念される出来事)が発生しているということであり、それがまさに「問題はどこにあるか?」を示唆するものです。
以上見てきたように、R1は特定の構造またはプロセスの中で発生します。そして、その中のどこかに懸念される出来事が存在しているということです。
このフェーズは、別の言い方をすれば、R1がなぜ発生したのかという要因分析に近いものです。しかし、細かい要因分析はフェーズ3で行うものですから、フェーズ2では要因を簡潔に述べるだけでいいのです。
さて、フェーズ1とフェーズ2はこれでおしまいですが、本の中には大事な項目がありました。それは、
①問題定義のフレームワークの図式化
②問題文の言語化(SCQへの変換)
の2点です。それぞれ解説していきましょう。
①問題定義のフレームワークの図式化
まずは下図をご覧ください。
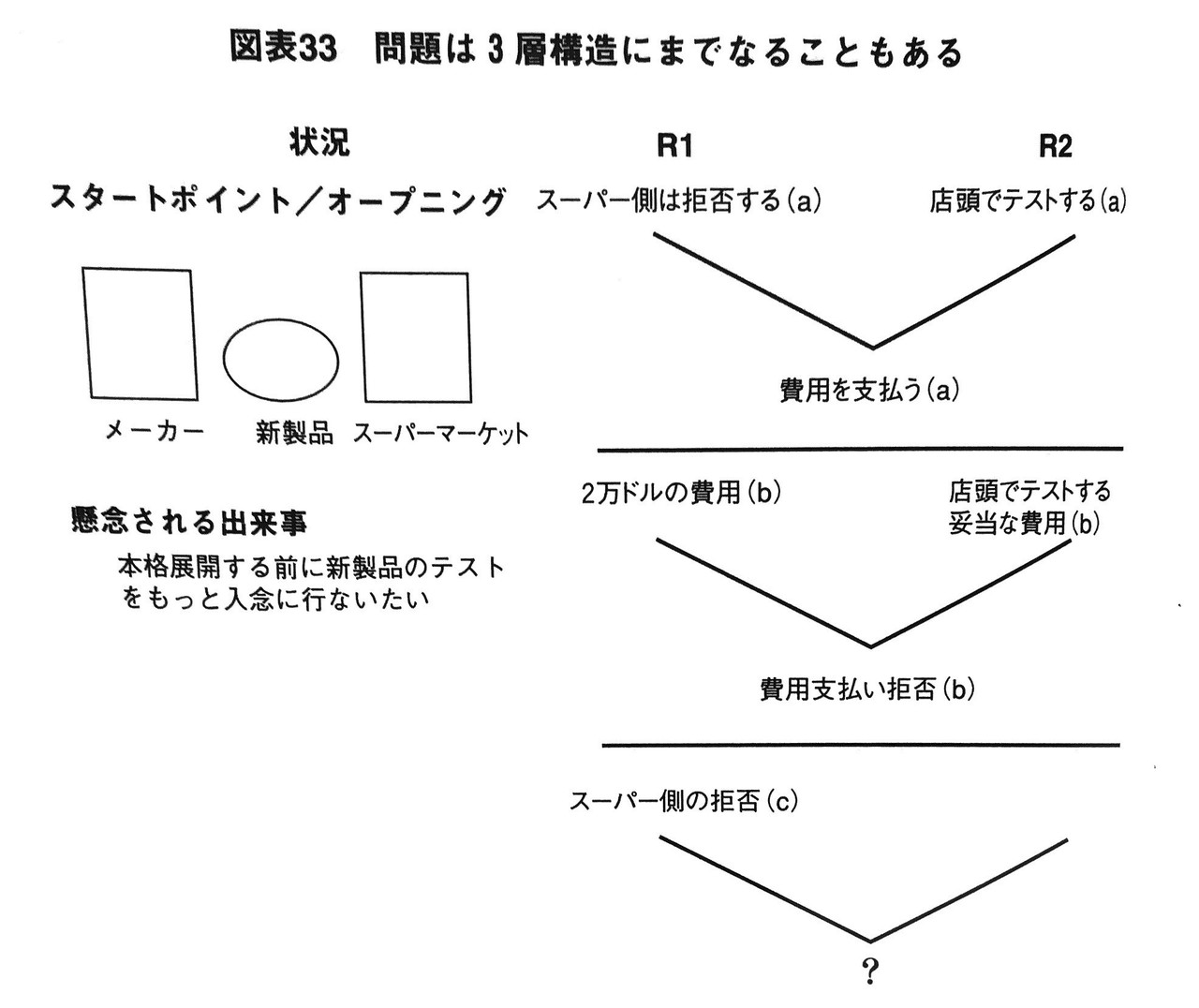
これが問題定義を図式化したものです。
右側にV字でR1とR2のギャップを書き、左側にR1を引き起こした状況(=スタートポイント/オープニング+懸念される出来事)を書きます。
なぜこのように図式化するかというと、問題部分を視覚化することによって目に見える形で足場を築けるからですね。つまり、頭の中を視覚的に整理することができるということです。
②問題文の言語化(SCQへの変換)
定義された問題をSCQに変換しますが、そもそもSCQとは何でしょうか。SCQとは、
Situation(状況):読み手にとって既知の時間的・空間的状況
Complication(複雑化):状況の中で発生し、疑問の引き金となる出来事。読み手が知る最新の情報。
Question(疑問):複雑化によって生じた疑問文で表現される事柄
の3つのことです。
わかりにくいかと思いますが、SとCは読み手(1人で問題解決する時は自分)にとっての既知の情報であり、Qを生じさせるものです。そして、Qは読み手にとっての未知の情報であり、答え(解決策)を与えるべき疑問です。
SCQを構成することにより、疑問の由来、つまりなぜ読み手に疑問が生じたのか、どこから疑問が生じたのかがはっきりと見えてきます。
例えば、「この問題に対してどのような解決策が考えられるか?」という疑問があるとしましょう。この時、疑問に対する答えを早急に出すのではなく、なぜその疑問が生じたのかを明らかにする必要があります。例えば、利益が低下したなどです。これはComplicationに相当します。そして、そのComplicationがどのSituationで発生したのかを考えてみると、既存の利益構造(利益=売上ーコストなど)から発生していることがわかります。つまり、Situation(既存の利益構造)があり、その中で何かが起こり(利益が低下した)、それが疑問を生じさせたということです。
この例を見ればわかると思いますが、ComplicationとSituationは既知の情報になりますね。
このように、1つ1つ掘り下げをすることによって何故疑問が生じたのかを明らかにします。そうすることで、その疑問が本当に正しいのかどうか、解決策を与えるべきかどうかを明らかにすることができます。
順序を辿っていくと、QはCによって生じ、CはSの中で生じるので、疑問を見出した後にSituationとComplicationを辿ります。つまり、Q→C→SあるいはQ→S→Cの順で辿ると、それぞれが見えてきます。
ところで、なぜ既知の情報と未知の情報を明らかにする必要があるのでしょうか?答えは単純で、推論の定義が既知の情報から未知の情報を導くことだからです。
このことは、IQテストを思い浮かべれば容易に理解できるのではないでしょうか。IQテストでは、いくつかの図形や数列が与えられて「?」を推測する問題が与えられます。つまり、いくつかの図形(=既知の情報)から?(未知の情報)を導きます。
問題解決の文脈では、未知の情報はQuestion(=R1からR2に到達するための方法)に該当しますね。推論の定義に従えば、問題解決をするには現時点でわかっていることを手掛かりにして解決策を導く必要があります。なので、「今わかっていることは?」という問いかけをして、「そこから何が言える?」と示唆を出してみるのもポイントだったりします。
では本題に移りましょう。問題を定義した後にSCQに変換するにはどうしたら良いでしょうか?
これは、問題分野において読み手がどこまでその問題に精通しているかによって異なります。SとCは読み手にとって既知の情報で、Qは読み手にとって未知の情報だからですね。したがって、書き手は読み手がどこまで知っていてどこまで知らないのかをはっきりさせる必要があります。それによってSCQのパターンが変化します。
SCQのパターンは7通りあります。
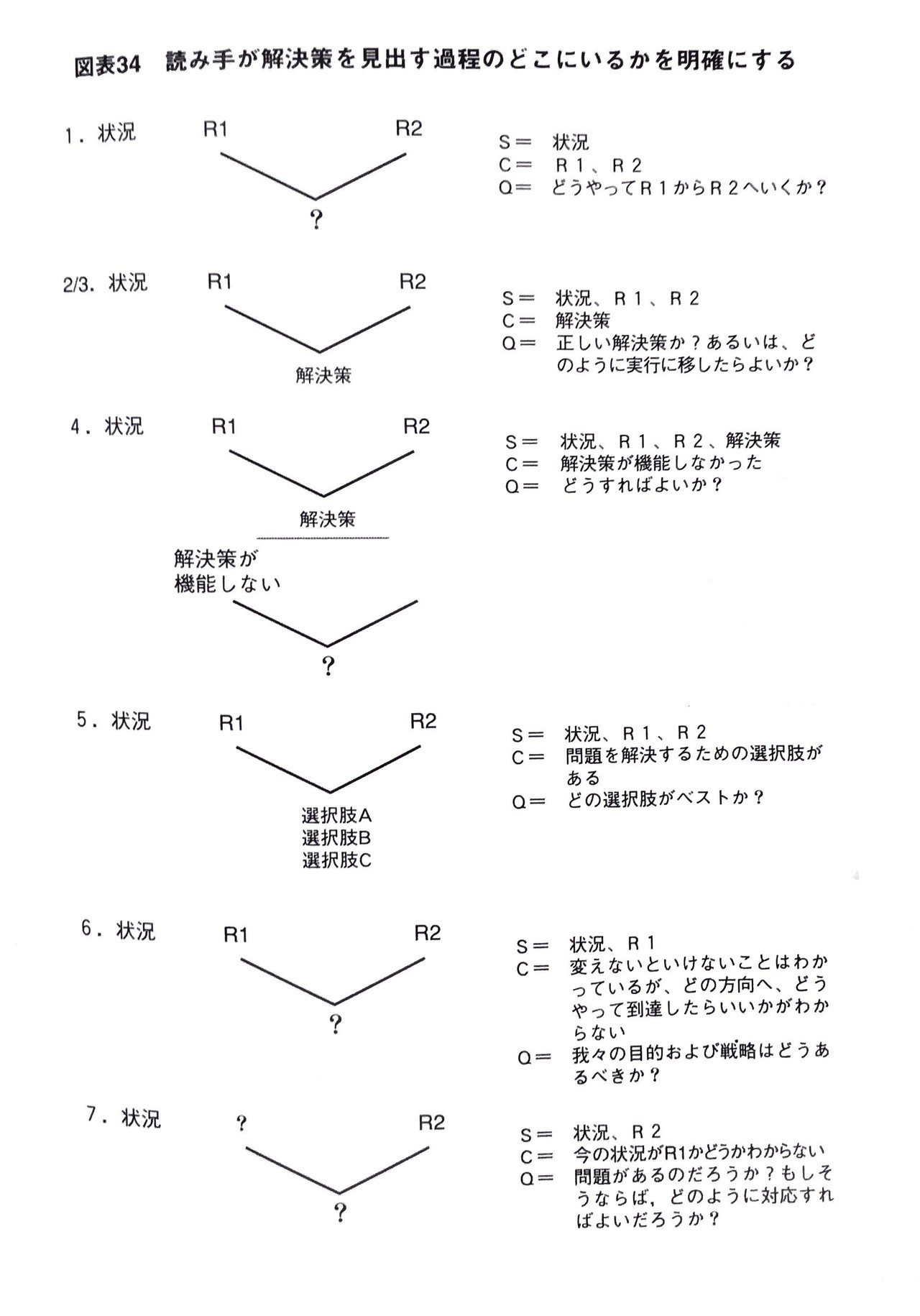
図を見て、「7つも覚えるのは大変だ」と思う方もいるかもしれませんが、これを覚える必要はありません。どのパターンを取っても、読み手はR1からR2に移動したいだけですから。それぞれを詳しくみてみましょう。
1.「目標と現状は分かっているけど、そのための解決策がわからない」というパターンですね。よくあるパターンです。例えば、今偏差値60で早稲田大学に合格したいけど、何をしたら良いの?と相談を持ちかけられたり、自分で頭を悩ませるパターンです。
読み手にとってはR1とR2、状況が既知の情報です。あるSituationの中で、Complication(R1とR2)が引き起こされており、そしてそのComplicationの中で、どうしたら良いのか?というQuestionが発生しています。
2.「目標に到達するために行動はしているけど、このやり方で本当に合っているのか?」と疑問に思うパターンです。例えば、英検準一級を取るために洋書を多読しているけど、本当にこれで英語力が身につくのか?と疑問に思うパターンですね。
読み手にとっては、正しい解決策かどうかが疑問ですから、その疑問を引き起こしているのは現在実行している解決策であり、その解決策は特定の状況、R1、R2の中で発生したものと言えます。
3.「目標に到達するための解決策は分かっているけど、どうしたらこの解決策を実行できるのか?」と疑問に思うパターンです。例えば、英検準一級を取るために洋書を多読していて、それが正しいのは分かっているけど、洋書を読むコツや方法が分かっていないケースですね。
読み手にとっては、どうしたら解決策を実行できるのかが疑問ですから、その疑問を引き起こしているのは現在実行している解決策であり、その解決策は特定の状況、R1、R2の中で発生したものと言えます。
4.「解決策を実行したが効果が上がらなかったので、R2に到達するための代替案を考えて欲しい」ということです。これは解決策そのものが疑問を引き起こしているというよりは、解決策を実行しても機能しなかったことが疑問を引き起こしているので、これがComplicationに該当し、読み手が知る最新の情報です。そして、解決策が機能しなかったことは、状況、R1、R2、解決策の中で起こっています。
5.「選択肢が複数あるがR2に到達するためにはどれが最善か?」ということです。このパターンの場合、Complicationは解決策の選択肢であり、それが疑問を引き起こしています。
6.「現状を変えないといけないことは分かっているが、目標や戦略が定まらない」ということです。これはよくありますね。漠然と今の自分のままではマズイことを理解しているが、目標や戦略が定まらないパターンです。
7.「目標は分かっているが、今の自分たちに問題があるのかどうかわからない」ということです。これもよくあるケースですね。
以上見てきたように、どのパターンをとっても読み手はR1からR2に到達したいだけです。1~7をよくみてください。解決策を求めるのも、正しいかどうか確認するのも、解決策の実行方法を尋ねるのも、代替案を求めるのも、全てR1からR2に移動したいから引き起こされている疑問です。
ですから、何が読み手にとって既知の情報で、何が読み手にとって未知の情報かを知ることができれば良いだけです。
SCQの話は複雑でわかりにくいかもしれませんが、イメージとしては数学や理科の問題文の作成ですね。例えば数学の問題では、
校庭に、南北の方向に一本の白線が引いてある。ある人が白線上のA点から西へ5メートルの点に立ち、硬貨を投げて、表が出た時は東へ1メートル進み、裏が出た時は北へ1メートル進む。白線に達するまで、これを続ける。
(1)A地点からnメートル北の点に到達する確率Pnを求めよ
(2)Pnを最大にするnを求めよ
といった問題が出題されますが、数学や理科の問題文には与えられた条件と求めるべきものの2要素が含まれています。つまり、与えられた条件をAとして求めるべきものをZとすると、数学の問題ではA→B→C→…→Zという道筋を作ることによって問題を解決します。
同様に、現実の問題解決でも、現状をR1、目標をR2として、様々な条件を考慮しながら、R1→…→…→R2という道筋を作ることによって問題を解決します。
そして、数学や理科と同様に、問題を言語化することによって自分や読み手の頭の中を整理し、効率的な問題解決を図ります。
例えば、「いま我々はR1の状況に陥っている。それを引き起こした構造/プロセスは○○であり、その中にR1を引き起こした原因がある。この時、R2に到達するための方法を提示せよ。ただし、条件は以下の通りとする。①〜②〜③〜」
といった感じで問題を文章化します。
イメージとしてはこうなりますね。あくまでイメージです。
図式化をしたら、SCQ(既知の情報と未知の情報)を意識しながら問題文を作成してください。
●第8章のまとめ
第8章では、
フェーズ1:問題はありそうか?
フェーズ2:問題はどこにあるのか?
について解説しました。
この章は、書籍では「問題を定義する」という名称づけがされていましたが、問題を定義するということは問題文を記述するということを意味しています。つまり、数学や理科の問題文のように、何が条件で、何が求めるべきもの(R2)で、何が現状(R1)なのか、R1が発生した状況は何なのかを文章として記述します。この作業を終えて初めて、要因分析や解決策立案の作業に取りかかることができます。
繰り返しますが、フェーズ1ではR1とR2を図式化し、フェーズ2ではR1が発生した状況を図式化します。
【第9章 問題分析を構造化する】
第9章では、フェーズ3〜5を扱います。
フェーズ3は問題はなぜ存在するか?つまり、問題が生じたいくつもの原因を図式化して真因を特定するフェーズです。
フェーズ4では、フェーズ3によって発見された真因に対して考えられる解決策の候補をいくつかリストアップし、図式化します。
フェーズ5では、解決策を絞り込んでただ1つの解決策を導きます。
●フェーズ3 問題はなぜ存在するか?
フェーズ3では、要因分析を行います。フェーズ2でも要因分析を行いますが、フェーズ3はそれをさらに深く掘り下げたものだと考えれば良いです。たとえば、フェルミ推定では、数量を求めるための全体像を表す式を作成したあと、その式をさらに分解していきますよね。それと同じです。なので、フェーズ2の段階でかなり大きな枠組みを作ってあげることが要因分析を効率的に行うコツになります。何となくそれっぽい要因をリストアップして構造化するのではなく、フェーズ2で明らかになった要因の全体像をさらに深く掘り下げていくことがフェーズ3のポイントです。
というか、連鎖分析プロセスはアブダクション(仮説思考)の推論順序にしたがったものですから、フェルミ推定は連鎖分析プロセスの解き方を反映します。フェーズ1:問題が与えられる。フェーズ2:式の全体像を作る。フェーズ3:全体像を掘り下げて仮の数値を入力する。フェーズ4:数値を修正するなどして、いくつか仮の答えを出す。フェーズ5:仮の答えを決定する
ですね。フェルミ推定を速く解ける人なら分かるかもしれませんが、連鎖分析プロセスによる問題解決は一見複雑に見えてスピード感のある方法です。
では、要因分析のイメージを掴むために以下の図をご覧ください。
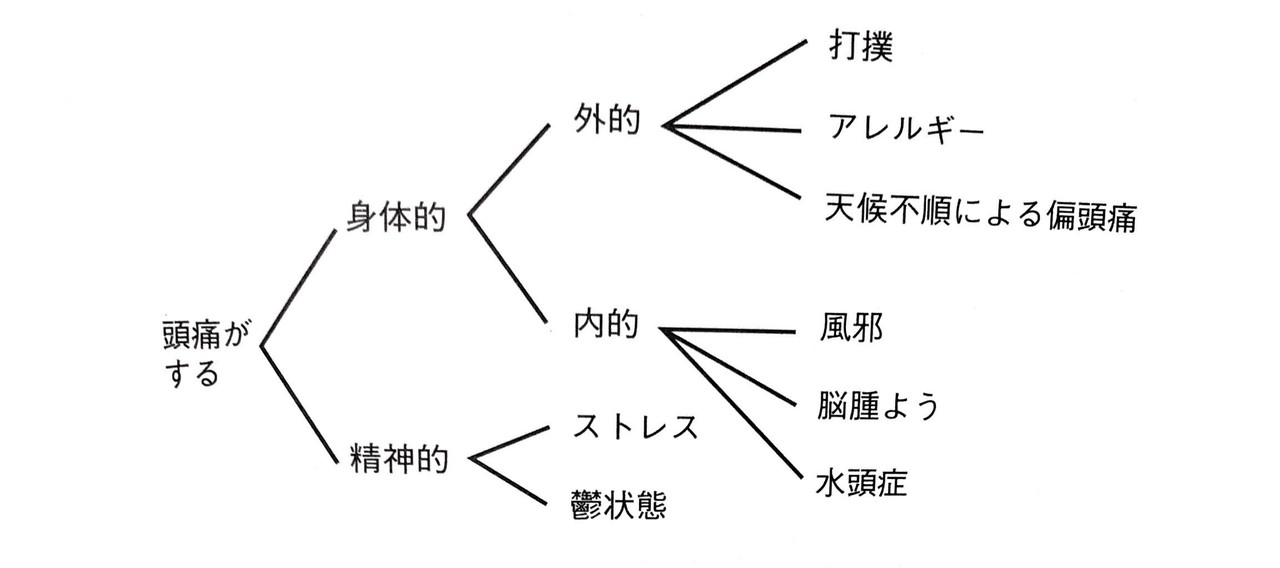
R1は「頭痛がする」ですが、それを引き起こす原因には様々なものがあります。図のように考えられる原因を網羅的にリストアップしたのち構造化(=要素分解して図式化すること)し、ただ1つの真因(=論点)を特定します。これが要因分析です。ここでは、風邪が論点に決まったと仮定しましょう。その場合は風邪を治すための解決策を考えて実行する必要があります。
また、ツリーの上位ポイントと下部ポイントの関係は、抽象と具体の関係にあるか、原因と結果の関係にあります。構造化の方法は詳しく後述しますが、この図では抽象と具体の関係にありますね。
では、要因分析の具体的な方法論について解説していきましょう。
本の中では、要因分析を行うためのフレームワークを「診断フレームワーク」と名付けています。これは臨床医の診断方法にちなんだ名前ですね。臨床医は、患者に詳細情報を聞いたりCTスキャンを行うことによって症状を引き起こしている原因を特定していきます。
これと同様に、種々の問題解決においても、想定される原因をリストアップして不要なものを消去して真因を特定する必要があります。このような類似点があるため、診断フレームワークと名付けられているのでしょう。
診断フレームワークには三種類あります。
①構造:物質的なものであれ、概念的なものであれ、全体を部分に分けるのが構造によるグループ化。具体例は後述する。
②因果関係:ツリーの上部ポイントと下部ポイントが結果と原因の関係になる
③分類:分類には二種類ある。類似性による分類と選択肢による分類。
前者は、ツリーの上部ポイントと下部ポイントが抽象と具体の関係になる。例えば、論点候補a1,a2,a3を共通する特徴Aでまとめると、Aという上部ポイントが発生し、それに対して具体部(a1,a2,a3)が連なる。
先ほど挙げた「頭痛がする」をR1とした図は、分類に基づいたグループ化である。
後者は、選択式のフローチャートをイメージすれば分かりやすいだろう。例えば、投資家適性を測る選択式のフローチャートでは、Yes/No形式で選択肢を分岐させ、あなたはバリュー投資に向いている、FXに向いている、不動産投資に向いている、債券投資に向いている、などの判定を行う。これとほぼ同じだ。ただ、ほぼ同じであるものの、これは要因分析のための選択肢ではない点が異なる。あくまでイメージを掴むためのとっかかりとして捉えてほしい。
では、それぞれを詳しく見ていきましょう。
①構造
構造によるグループ化とは、物質的なものであれ概念的なものであれ、全体を部分に分けることによるグループ化です。画像を貼りますので、参考にしてください。
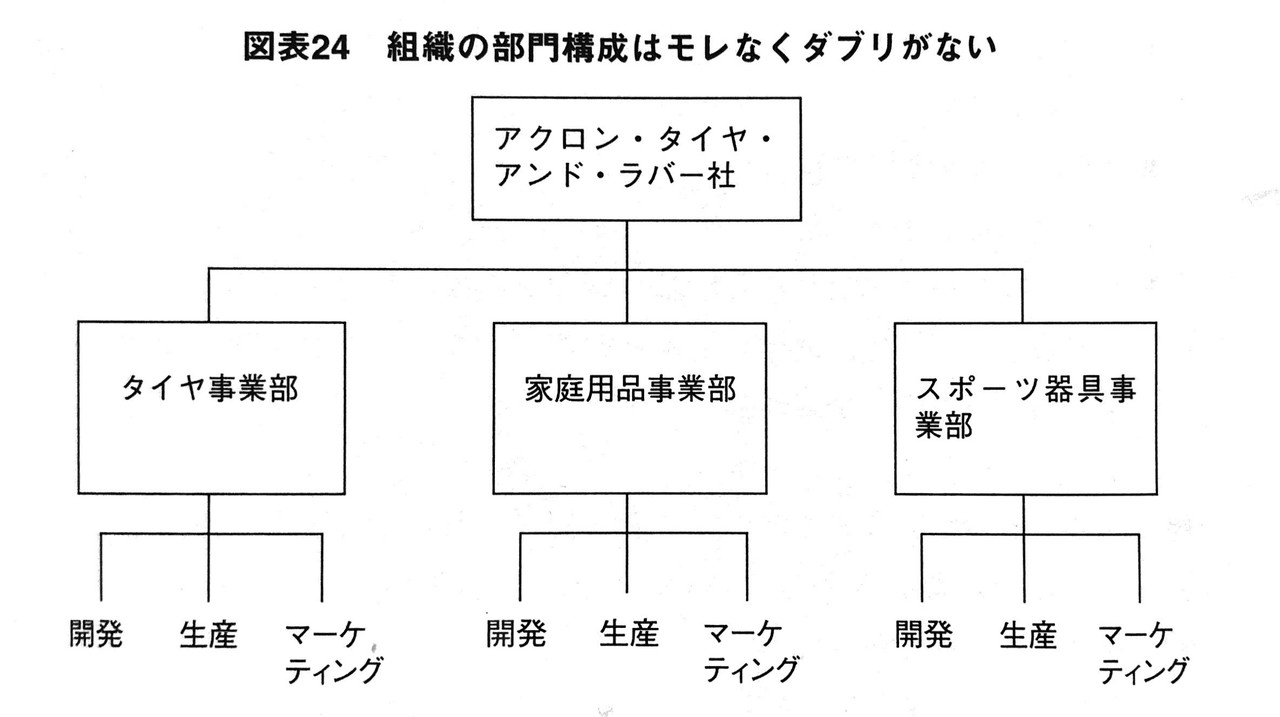
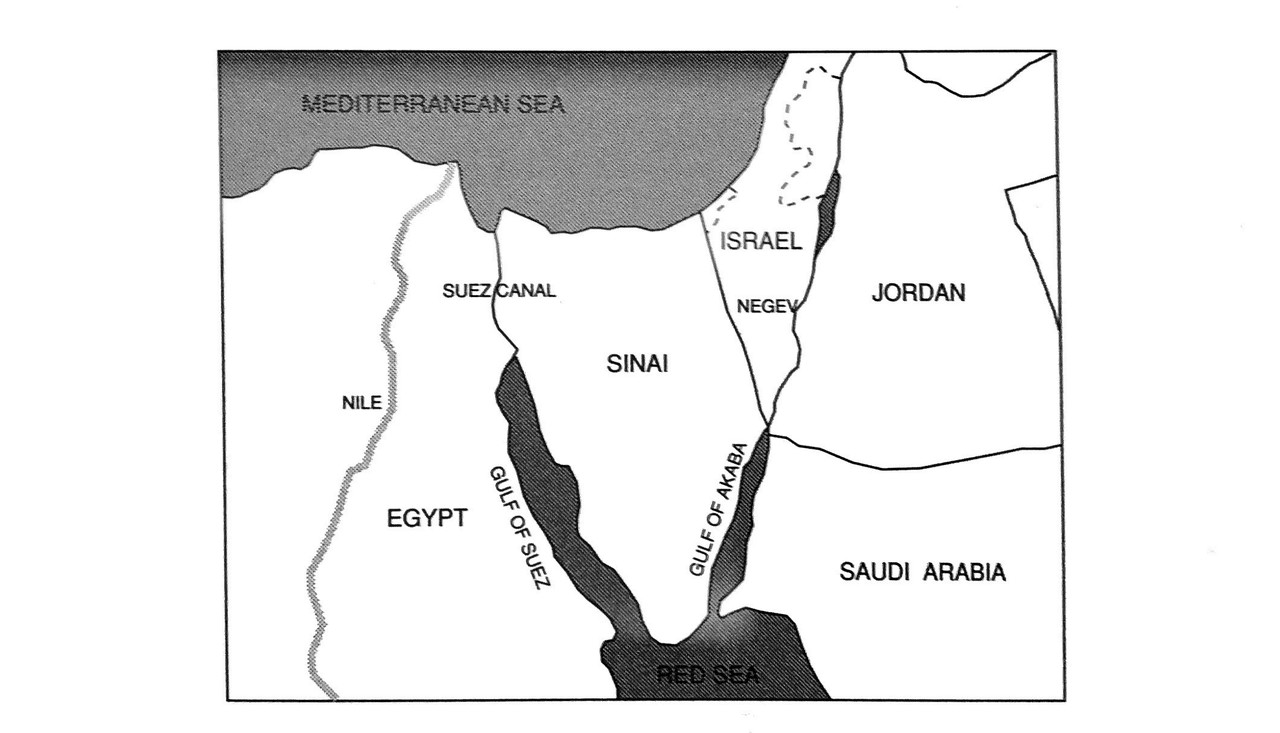
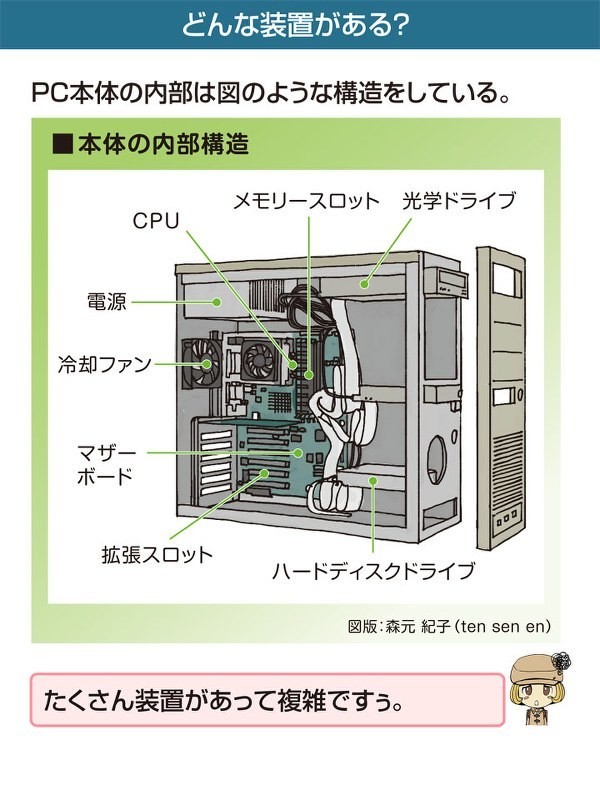
1枚目と2枚目の画像は組織図です。組織全体を各部門に分解しています。これは概念的なものの構造を分解した例ですね。
3枚目の画像はシナイ半島の地図です。地域別に分解されてますね。これは眼に見えるものの構造を図式化した例です。
4枚目の画像はPCの内部構造です。PCをパーツごとに分解するとこうなります。物質的なものの構造を分解した例ですね。
構造とは何か、イメージが掴めたでしょうか。
では構造によるグループ化について解説しましょう。
フェーズ2で述べた通り、R1は何らかの構造やプロセスの中で発生します。構造によるグループ化は、フェーズ2でR1が特定の構造に起因していることが明らかになった場合に用いられますが、このグループ化は、主に会社の組織図や流通システム、機械の構造を図式化する際に用いられます。まずは下図をご覧ください。
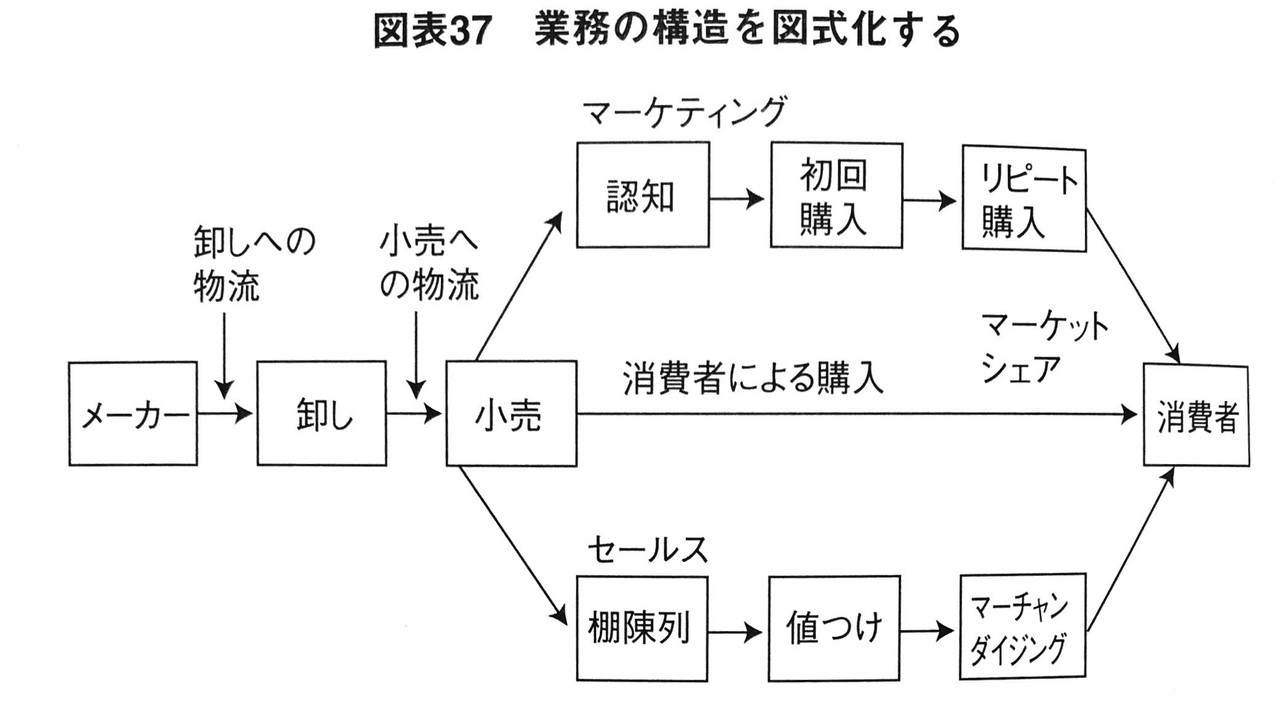
この図は、小売店の業務(販売・マーケティング)を図式化した例です。
このように図式化することで、流通構造の中のどこに問題が潜んでいるのかがわかり、真因を特定することができます。
リストアップされた論点候補はこの構造の中に組み込めば良いのです。例えば、シェア低下(=R1)の原因の候補は、消費者に対する商品認知が不十分であることや、購入の動機付けが足りないことなどが考えられますが、これらの論点候補を構造の中に組み込むことによって論点候補を視覚化させ、論点の特定を容易にしてくれます。
別の例も挙げましょう。下図をご覧ください。
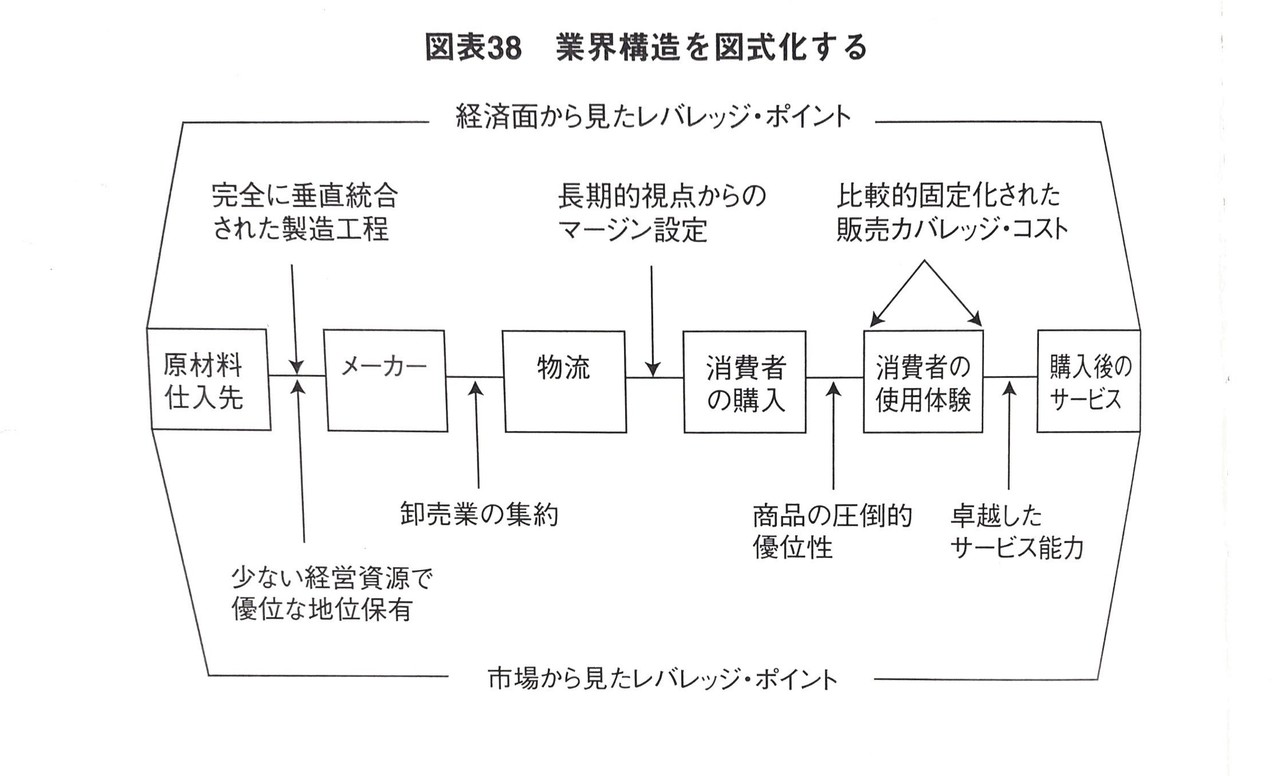
先ほどの構造よりもやや複雑ですね。
図をよく見ると上部に「経済面から見たレバレッジ・ポイント」と書かれており、下部に「市場から見たレバレッジ・ポイント」と書かれています。これは何かと言うと、サプライチェーンの中に存在する改善効果が高いポイント(=レバレッジ・ポイント)のことです。
レバレッジとはてこの原理のことであり、FXで頻出する用語ですが、ビジネスの場面では「少ない労力で大きな成果を出すこと」をレバレッジと言い、「レバレッジが利く」という用い方をします。この図では、レバレッジ・ポイントとして上半分に3つ、下半分に4つの要素が挙げられていますね。
このように構造を図式化して、「構造の中のどこにレバレッジ・ポイントがあるか」「構造の中のどこに付加価値があるか」「コストはそれぞれに対してどのように配分されているか」「利益や資産はどう配分されているか」などを組み込んでいきます。
②因果関係
因果関係によるグループ化は、特定の結果からそれを引き起こす原因を辿っていく方法です。因果関係によるグループ化は3パターンあります。
(1)要素の構造
これは、R1を引き起こしている要素を名詞で記述し、ツリー状にグループ化する方法です。下図を見てください。この図では、財務構造をツリー状で並べて整理しています。上部ポイントと下部ポイントが結果と原因の関係になっていることがお分かりでしょうか。つまり、ROIは営業利益や資産によってもたらされ、営業利益は売上と費用によってもたらされるということです。
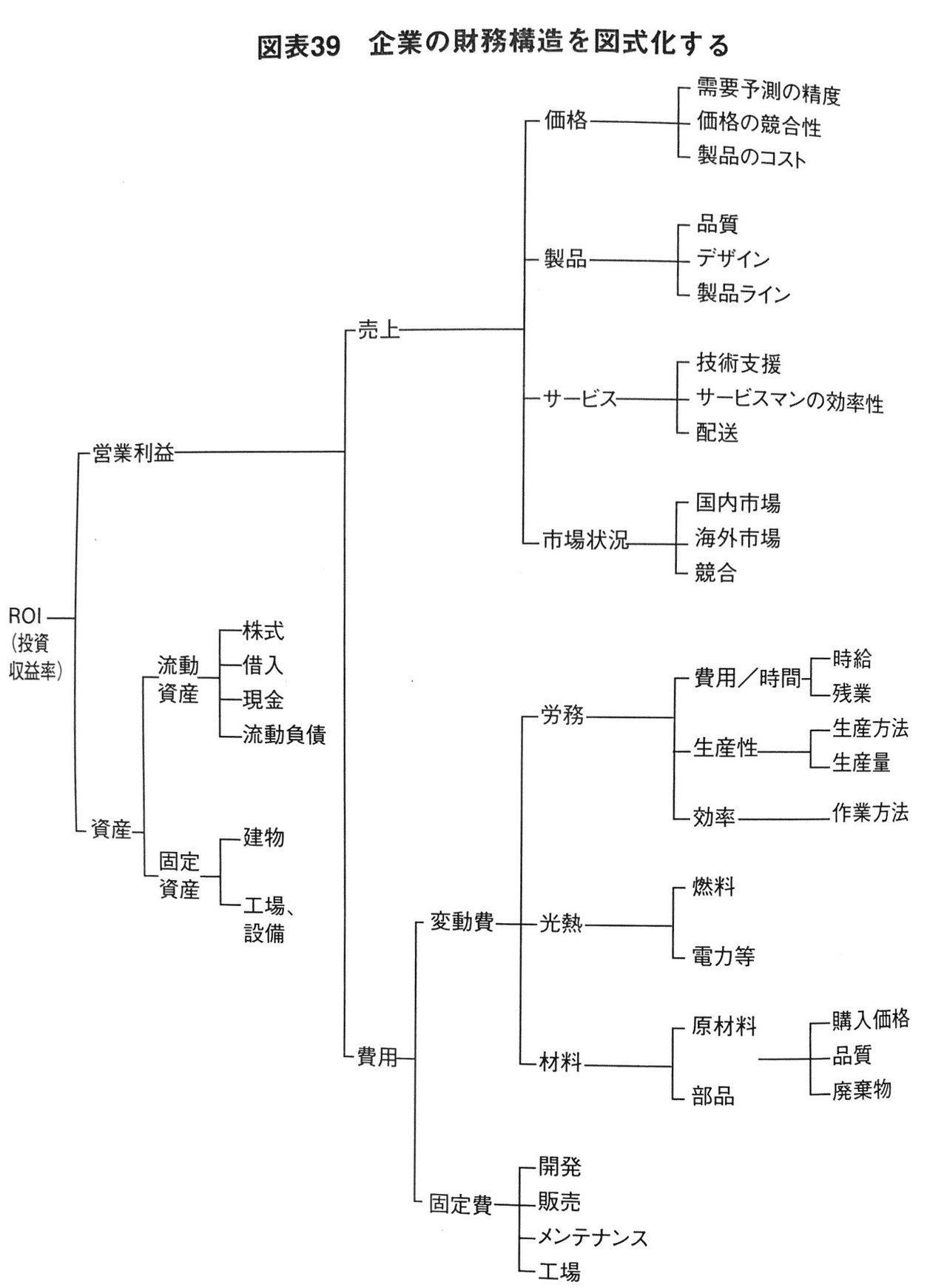
もしあなたがROIの向上を図りたい場合、ROIを構成する要素である営業利益や資産を深堀りしていけば、その中のどこかにROIを上げるためのレバレッジ・ポイントが潜んでいるはずです。
しかし、この図のままでは名詞を並べているに過ぎないので論点を発見することができません。
したがって、現状の数字をツリー上に直接書き込むによって、R1(=ROIの低さ)を引き起こしている原因が売上低下によるものなのか、高いコストによるものなのか、商品要素によるものなのか、価格施策によるものなのか、といった判断をする必要があります。
つまり、どの要素が足かせになっているかが明白になり、論点を絞り込むことができるということです。
また、R2を引き起こす状態の数字(=各要素の理想の数字)はどうなっているかを直接書き込むことによって、ベンチマークを行うことも可能です。
(2)R2に到達するために必要なタスクの構造
これは、先ほどの要素の構造とは異なり、R2に到達するために必要とされるタスクやR2そのもの(この場合は、そのタスクを実行することがR2そのものとなる)を最上部ポイントに置き、そのタスクの達成をもたらすような行動を深堀りしていきます。
下の図では、1株当たり利益の増大が「営業利益と営業資産の増大」と「財務体質の強化」によってもたらされることが分かります。つまり、上部ポイントと下部ポイントは結果と原因の関係にあるということです。
また、このように図式化することによって、あなたがどんな行動が必要で、どんな行動が必要でないかを視覚的に整理することができます。
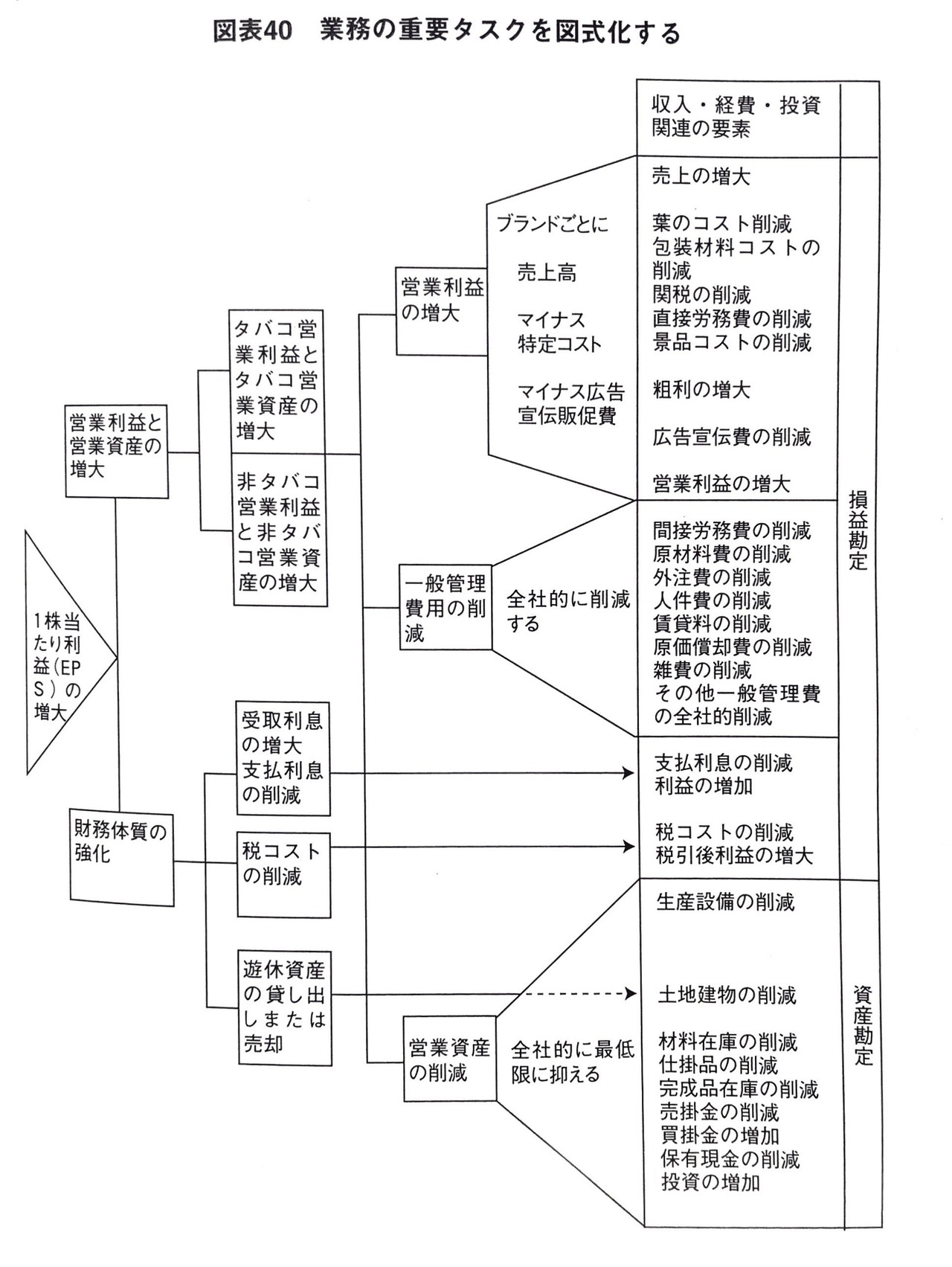
(3)R1を引き起こしている望ましくない活動の構造
これは、R1を引き起こしている活動またはR1そのものを最上部ポイントに置き、それを引き起こす活動を深堀りしていく方法です。(2)と同様に、上部ポイントと下部ポイントが結果と原因の関係になっていることがわかるでしょう。
しかし、(2)とは違い、(3)では各リストが否定的な言葉で記述されます。(2)がR2を引き起こすタスクを掘り下げるのに対して,(3)はR1を引き起こす活動を掘り下げるのですから、当然と言えば当然ですね。
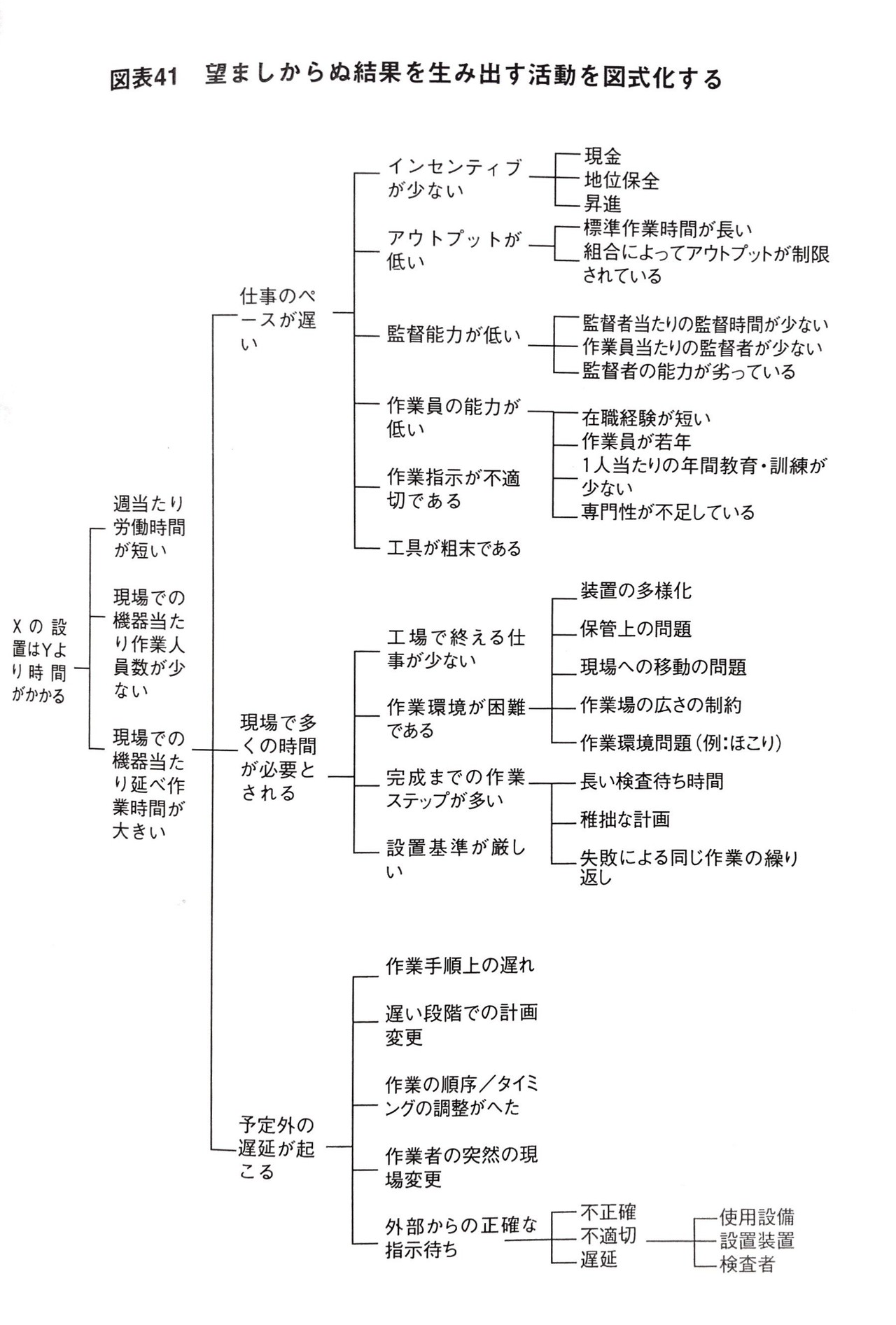
③分類
分類によるグループ化は、類似性による分類と選択肢による分類の二種類あります。では、それぞれ見ていきましょう。
(1)類似性による分類
そもそも、類似性による分類とは何でしょうか。類似性というのは共通する特徴のことです。
いくつか例を挙げて説明しましょう。
男女で言えば、70億人程度いる全ての人間を、「男という特徴持った人間」と「女という特徴を持った人間」の2つの共通要素を基準にして分類しているということです。
さらに、動物の分類は、全ての動物を「哺乳類という特徴を持った動物」や「爬虫類という特徴を持った動物」や「両生類という特徴を持った動物」などの共通する特徴を軸にして分類していますね。
これが類似性による分類です。
問題解決の文脈で言えば、リストアップされた論点候補を「この論点候補とあの論点候補は共通する特徴を持っているな。よし、じゃあこの2つを同じグループにまとめよう」とする知的操作のことです。
ちなみに、類似性による分類は抽象化(=共通点を抽出してグループ化)を伴いますので、上部ポイントと下部ポイントは抽象と具体の関係になります。
イメージは掴めましたかね。では、類似性によって分類する方法を説明します。下の図をご覧ください。
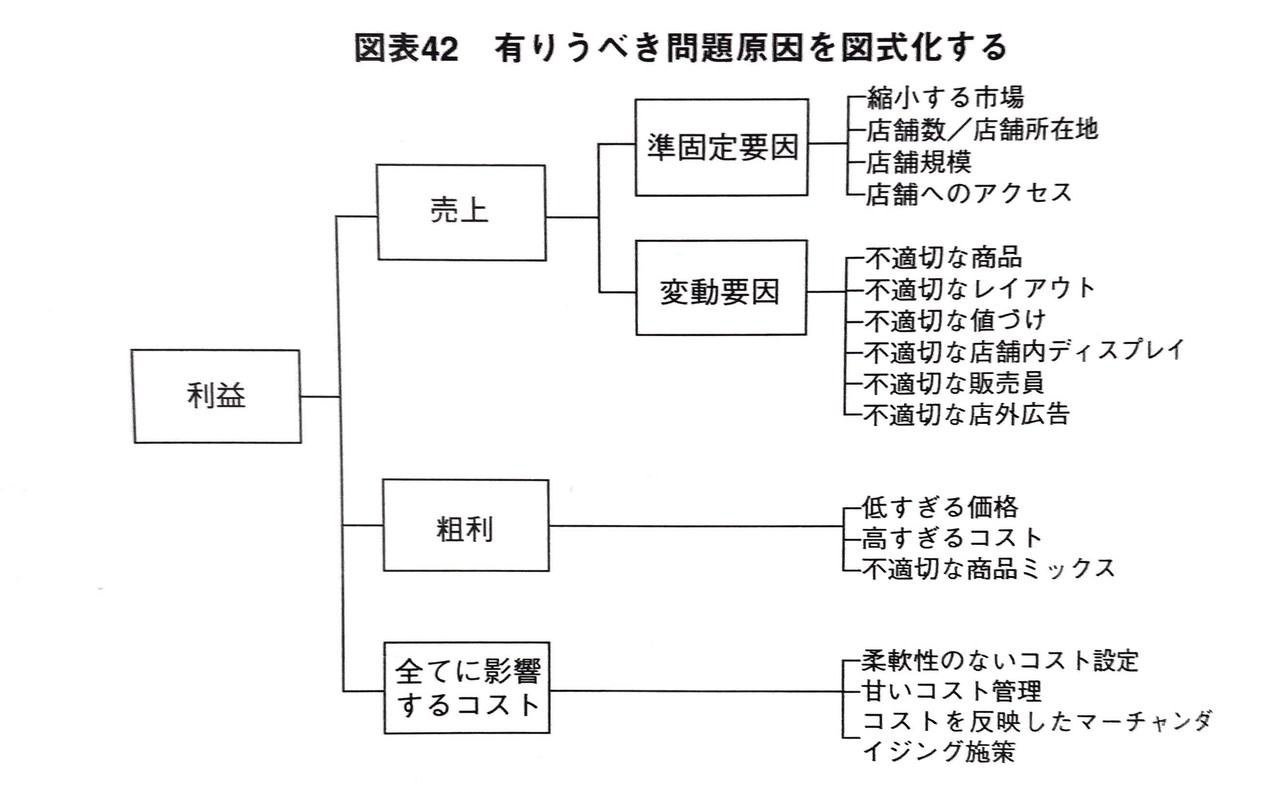
「有りうべき」とは、「有り得る」という意味です。
この図は、利益低下(R1)を引き起こした要因(=論点候補)をリストアップして、それぞれの要因を共通する特徴でグループ化したものです。
例えば、右上を見ると、縮小する市場、店舗数/店舗所在地、店舗規模、店舗へのアクセスと書いてありますね。これらの各リストは準固定要因という共通する特徴を持っているので、分類によるグループ化が可能ということです。
誤解してる方が多いかもしれませんが、類似性による分類は因果関係によるグループ化とはやや異なります。
図における上部ポイントと下部ポイントは確かに結果と原因の関係になっているのですが、因果関係によるグループ化は共通する特徴による分類を行なっていません。その点が異なります。
(2)選択肢による分類
選択肢による分類は、望ましくない結果(=R1)を引き起こす原因をYes/Noで判定して探っていく方法です。図を見てください。
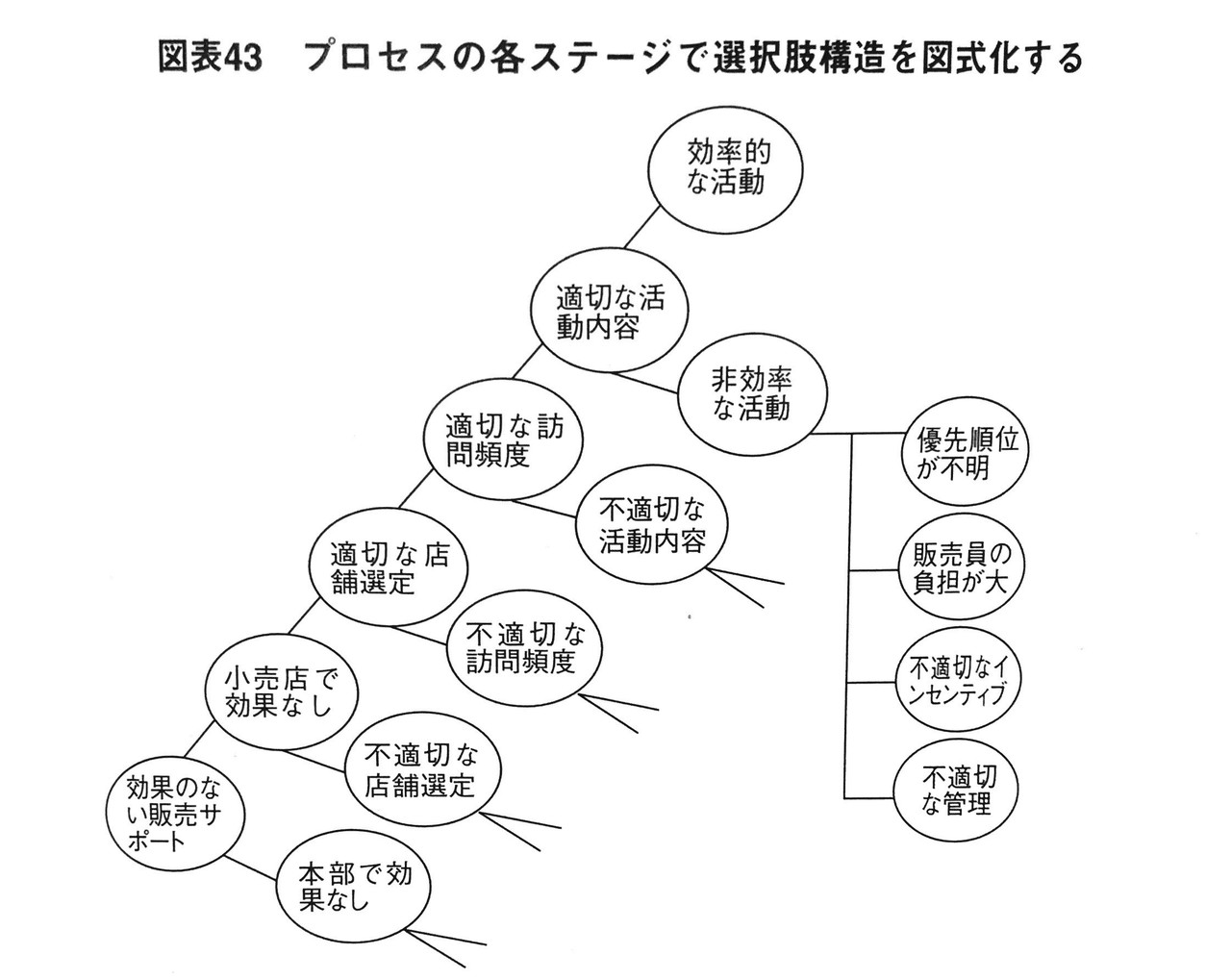
左下からスタートします。
もし販売サポートが効果的ではない(R1)なら、その原因は店舗レベル(1つ上)か商品本部レベル(1つ右)のどちらかです。もし店舗レベルで効果的でないなら、正しい店舗(1つ上)か間違ってる店舗(1つ右)かのいずれかが原因です。もし間違った店舗で効果が上がらない場合、間違った店舗選定自体が問題です(=店舗選定の時点で間違っていれば、その間違った店舗で頑張っても効果が上がらないということ)。 もし正しい店舗で問題が生じている場合、店舗訪問の頻度が正しい場合(1つ上)と不適切な場合(1つ右)とに分かれます。もし正しい訪問頻度の場合、訪問活動の内容が適切な場合(1つ上)とそうでない場合(1つ右)に分かれます。
このように、R1を引き起こした原因をYes/Noで判定していき、真因(論点)を絞り込みます。
この選択肢構造を作るコツは、選択肢を並べる順序です。論点候補を紙面上にリストアップしたら、各リストの関係を整理して時系列で並べ、このような選択肢の構造を作成します。
上の図では、販売活動の一連のプロセスを時系列で並べてると言えるでしょう。つまり、まず店を選定し(適切な店舗選定と不適切な店舗選定)、次に店を訪問(適切な訪問頻度と不適切な訪問頻度)し、活動を起こすというプロセスです。
この選択肢構造は複雑で難しいですが、時系列上のどこに問題があるかを探る上で強力な図式化です。
さらに、選択肢構造を発展させたものとして次のようなグループ化(連鎖マーケティング構造)もあります。
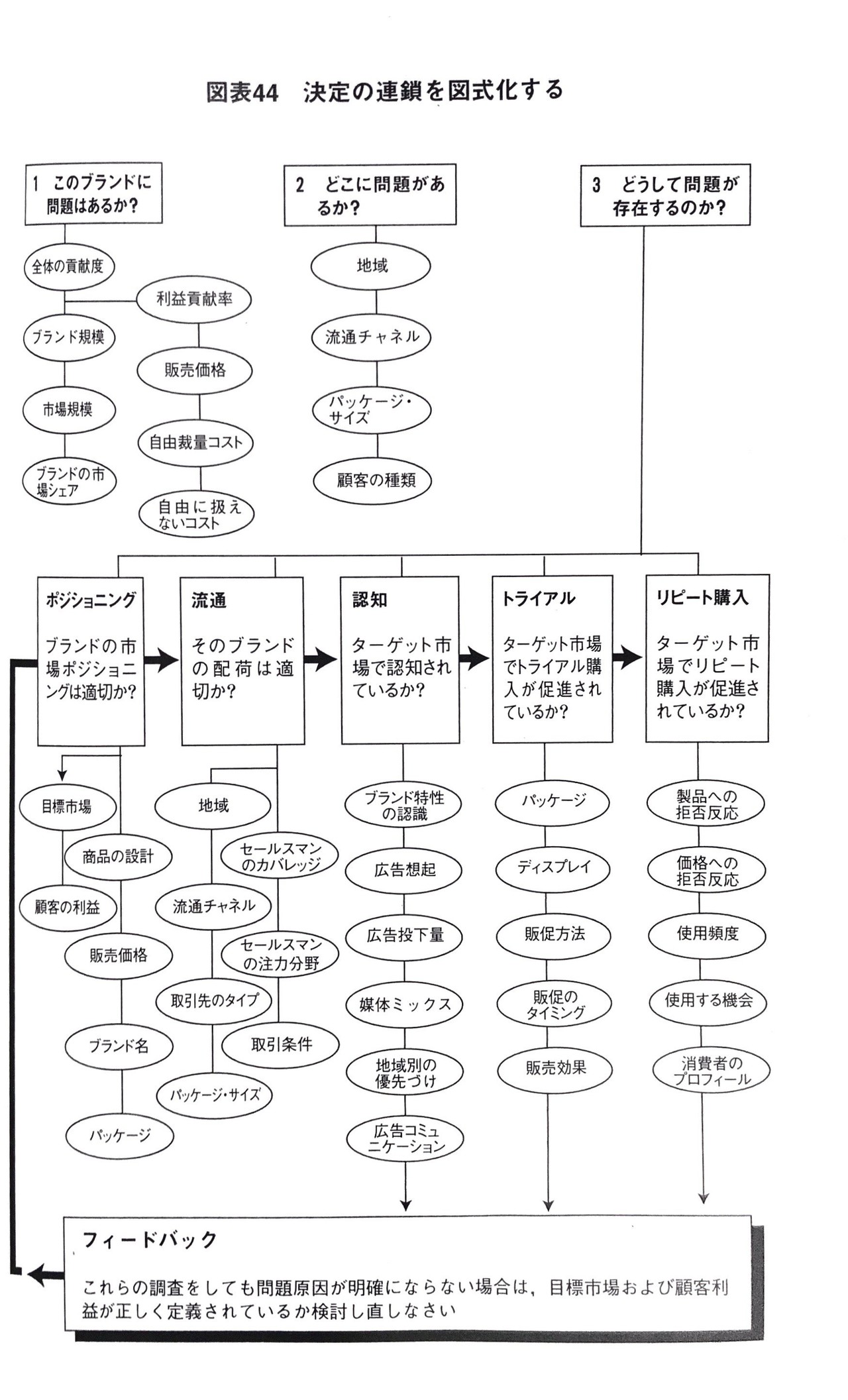
複雑なので一見しただけでは何を表しているのか分からないかもしれませんが、これは連鎖分析プロセスを選択肢構造で図式化しています。
フェーズ1では、問題(R2-R1)があるかどうかを確認します。
問題があるとしたら、全体の貢献度か?Noだとしたら、利益貢献率か?ブランド規模か?利益貢献率ではないとしたら、販売価格か?ブランド規模ではないとしたら、市場規模か?
このように、Yes/No判定をすることによって、問題があるかどうかを確認しています。
フェーズ2では、問題の所在を明らかにします。つまり、どのような状況(構造またはプロセス)から問題が発生しているかです。地域から起因しているのか?そうでないとしたら、流通チャネルか?といった具合にYes/No判定を行って問題の所在を特定して行きます。地域も流通チャネルもプロセスではなく構造ですね。
フェーズ3では要因分析を行います。図を見れば、ポジショニング→流通→認知→トライアル→リピート購入といったように、時系列の順序を反映していることが明らかでしょう。さらに、各ステップで選択肢を作成し、Yes/No形式による判定を行い、真因を特定しようとしています。
例えば、マーケティング・プログラムが適切ではないことを示すいくつかの分析結果が出たとしましょう。例えば、包装がよくない(流通)、広告の焦点がずれてる(認知)、販売促進活動がバラバラ(トライアル)、購入者は商品を十分な頻度で使用していない(リピート購入)などです。
ここでは、各ステップが時系列で並べられているため、左側で発見された問題は右側で発見された問題よりも優先的に解決する必要があります。つまり、購入者の商品の使用頻度を上げるよりも先に、販売促進活動を統制されたものにする必要がありますし、販売促進活動を統制するよりも先に、正しいセグメントに絞った広告を計画する必要があります。
以上で、論点候補をグループ化して図解する方法は終わりになります。
しかし、重要なことが3点あります。
①MECE(ミーシー)
②論点候補を表現する方法
③論点の絞り込み方
です。
①MECE
MECEとは、漏れなく(Mutually Exclusive)、ダブりがない(Collectively Exhaustive)ことです。つまり、図式上の各リストに見落としがなく、かつ重複するリストもないということです。
例えば、営業利益が低い原因を探すために因果関係のツリーを作成したとしましょう。この時、ツリー上に売上だけがリストされて費用がリストされてなかったら、真因を特定するのが難しくなります。
これと同様に、どのような問題を相手にするにせよ、漏れなくダブりなく原因をリストアップする必要があります。
ところで、MECE形式で原因をリストアップする必要性は何なのでしょうか?1つは、これまでに述べた通り、見落としを防ぐためです。
しかし、もう1つ重要な目的があります。
論点候補のリストアップの項でも述べましたが、抽象と具体の行き来をすることで異なる論点候補が浮上したり新しいアイデアが生まれることがあります。大事なことは、原因を漏れなくダブりなくリストアップするコツは抽象化であるということです。具体例を挙げましょう。
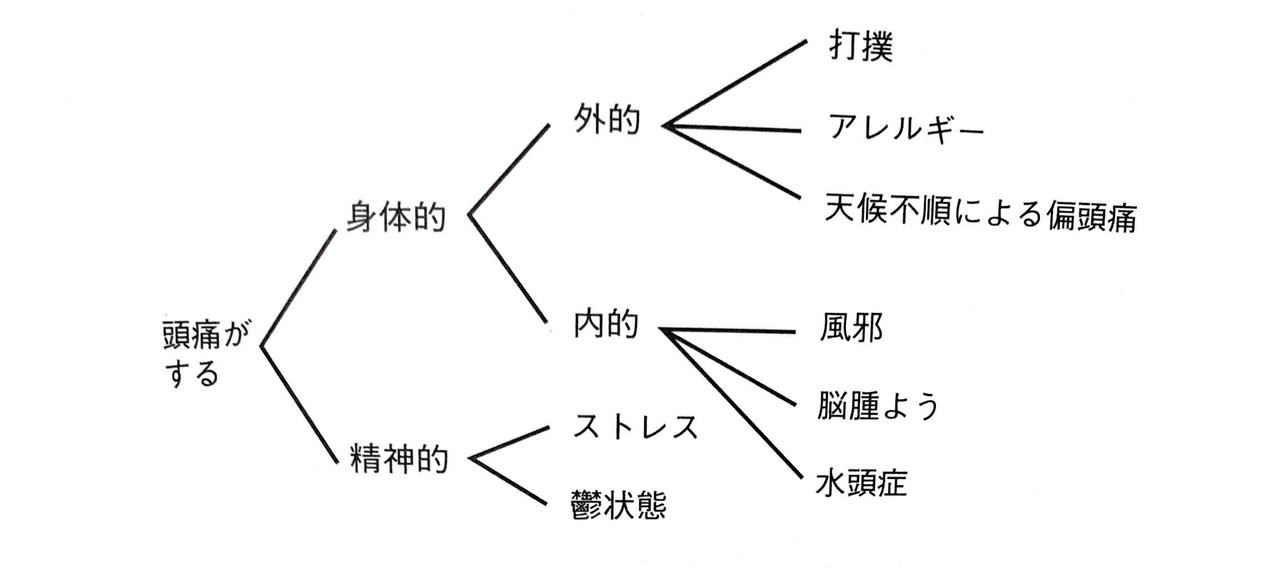
これは前の項でも出した画像です。
あなたが、頭痛の原因は風邪だと思っているとしましょう。この仮定のもと行う抽象化は、「風邪は身体的要因だ」です。しかし、あなたはここで気づきます。「身体は精神と対比される語だから、身体的要因があるということは精神的要因もあるのでは?」と考えます。つまり、同じレベルの異なる論点候補が浮上したということです。そして、「身体的要因と言っても、体の内部と外側に分かれるな」と考えます。これで、風邪が身体的要因の中でも内的要因に分類されることが分かりました。しかし、あなたには気になることがあります。「風邪が内的要因に分類されることは分かったけど、他にも内的要因に分類される原因はありそうだな」と。そこで、抽象と具体の行き来をします。「内的要因に分類される他の要因は何だろうか?」と考え、脳腫瘍や水頭症があることに気づきます。
以上のような知的操作(抽象と具体の行き来)を行うことで、抽象部に連なる他の原因として何があるかを探ることができます。
リストアップされた論点候補に共通する特徴をはっきりと言語化することで、抽象と具体の行き来が容易になりMECE分類ができるようになります。
さて、ここまで読んで、「とてもこんなことは出来ない」と思った方もいるでしょう。そこで、MECE分類を行いやすくするためのフレームワークをいくつか紹介します。
上の画像では、「物理的(身体的)と精神的」のフレームワークと「外的・内的」のフレームワークが使われており、これらのフレームワークによって抽象化が行われています。
もちろん、下図に書かれているフレームワークさえ覚えればMECE分類ができるようになるわけではありません。問題状況をよく観察し、臨機応変にMECE分類する必要があります。しかし、フレームワークを覚えておくことでMECE分類が非常に楽になることは間違いありません。
MECE分類がうまく出来なかったり、抽象部に連なる他の具体部が思いつかないこともあるでしょう。そういう場合は、虫食いのツリーを作りましょう。ツリー上に「?」などと書いておきます。こうすれば、未知の情報に足止めを食らうことなく論点特定の作業を前進させることが出来ます。
最後にフレームワークを用いる際の注意事項を説明しておきます。フレームワークを使うタイミングですが、フレームワークは論点候補をいくつかリストアップした後に使ってください。問題を与えられるやいなや、いきなりフレームワークで整理しようとする人がいますが、フレームワークに囚われた思考しかできなくなり、かえって視野を狭くしてしまいます。つまり、思考の盲点を発生させてしまうということです。用法・用量には十分気をつけましょう。
②論点候補を表現する方法
論点候補はあくまで現時点で原因であろうと思われる仮説でしかありません。そして、仮説は検証されるべきです。したがって、論点候補は検証可能な表現で記述する必要があります。
検証可能な表現とは、Yes/Noで表現される仮説のことです。論点候補を検証する際、論点候補が「どのように機能を再構築すべきか?」と表現されていたら、仮説の検証のしようがありません。一方、仮説が「機能を再構築すべきか?」といったようなYes/Noで判定が可能な表現になっていれば、仮説の検証は非常に楽なものとなります。
これは、フェーズ1で言及した論点(real problem)と課題(issue)の定義の違いと同じですね。論点には、論点ではあるが課題ではないもの(=Yes/No疑問文ではないもの)と、論点であり課題でもあるもの(=Yes/No疑問文であるもの)の2つがあります。検証を容易にするために、各論点候補はissueの形式で表現しましょう。
一応補足しておきますが、情報収集やリサーチはあくまで検証のために行うものであって、仮説を構築するために行うものではありません。
多くの人は順序が逆になっています。つまり、情報収集をしてから仮説の構築をしているということです。しかし、これではどこまで情報を集めれば良いのか見当がつきませんし、作業の8割〜9割程度の時間を情報収集に費やす羽目になってしまいます。
ですから、この順序を入れ替えましょう。まず最初に仮説を立てて、その仮説の検証をするために情報収集をすれば良いのです。そうすれば、情報収集に費やす時間は2割程度に削減されるので、結論を導いて実行に移すまでの時間が非常に短くなります。
論点候補を検証可能とするためにYes/No疑問文で表し、情報収集はあくまで検証のために行いましょう。
③論点候補の絞り込み方
これは本には書いていない方法ですが、論点候補を消去する方法には以下の3通りの方法があります。
①直観力ベース:既知のファクト(現象や観察事実)、経験、勘に基づいて、容易に消去できる論点候補から順に直観で消去していく。あるいは、「これだ」と思う論点を直観的に見抜く。
②論理力ベース:矛盾を見つけて論点候補を消去する。これには2つの方法がある。
(1)因果関係:「論点を解くことによって直接的に結果が得られる」と確信するまで論点を批判的に捉える。これは、行動のステップで因果関係を言語化して論理的な飛躍がないかどうかを確かめれば良い。例えば、年収1,000万以上の男と結婚すれば幸せになれると考えている婚活女子がいるとする。
この考えに論理的な飛躍がないかどうかを検討するために、ステップ形式で女性の頭の中を記述してみよう。
STEP1:年収1,000万以上の男性と出会う
STEP2:その男性と仲良くなり、付き合う
STEP3:数年後あるいは数ヶ月後、結婚する
STEP4:幸せになれる
このような時系列が存在するが、STEP3とSTEP4の間に論理的な飛躍がある。
結婚する→幸せになれるは本当に正しいのか?
年収1,000万以上の男性と結婚することで直接的に得られる結果は、年収1,000万以上の旦那を持つということだけだ。幸せになれると考えているなら、それはバイアスでしかない。
この女性のように、風が吹けば桶屋が儲かる的な発想をしている方は非常に多い。結婚して幸せになれるかどうかは間接的(=副次的)な結果にすぎない。
このように、因果関係を言語化して直接的に結果が得られるか?を批判的に検討することによって、論点候補を絞り込むことができる。
(2)比較:条件を同一にして他の業界や企業、人と比較してみる。「同じ条件・状況でも他の企業には当てはまっていない」と分かれば、論点候補から外すことができる。
例えば、利益低下の原因を探るケースを考えよう。この時、まず最初に考えることは、「同じ業界の競合他社も全て利益低下しているのか」である。もし利益が低下していない会社があれば、業界全体から来る原因ではなく、企業固有の問題であることが分かる。
③リサーチベース:直観力を駆使しても論理力を駆使しても消去できない論点があった場合、詳細を知っていそうな人(専門家など)にインタビューしたり、問題の依頼者にインタビューしてみたり、誰かとディスカッションしてみたり、インターネットや文献を参照して絞り込む。
最初は直観力ベースで絞り込みますが、直観で消去できないような判断の難しい論点は論理力を駆使して消去します。それでも判断できなければ、リサーチを行って絞り込みます。もちろん、順序に決まりはありませんので臨機応変に絞り込んで下さい。
●フェーズ4 問題に対し何ができるか?
フェーズ4では、解決策をリストアップしてロジックツリーの形式で図式化します。例を挙げますので、下図をご覧ください。
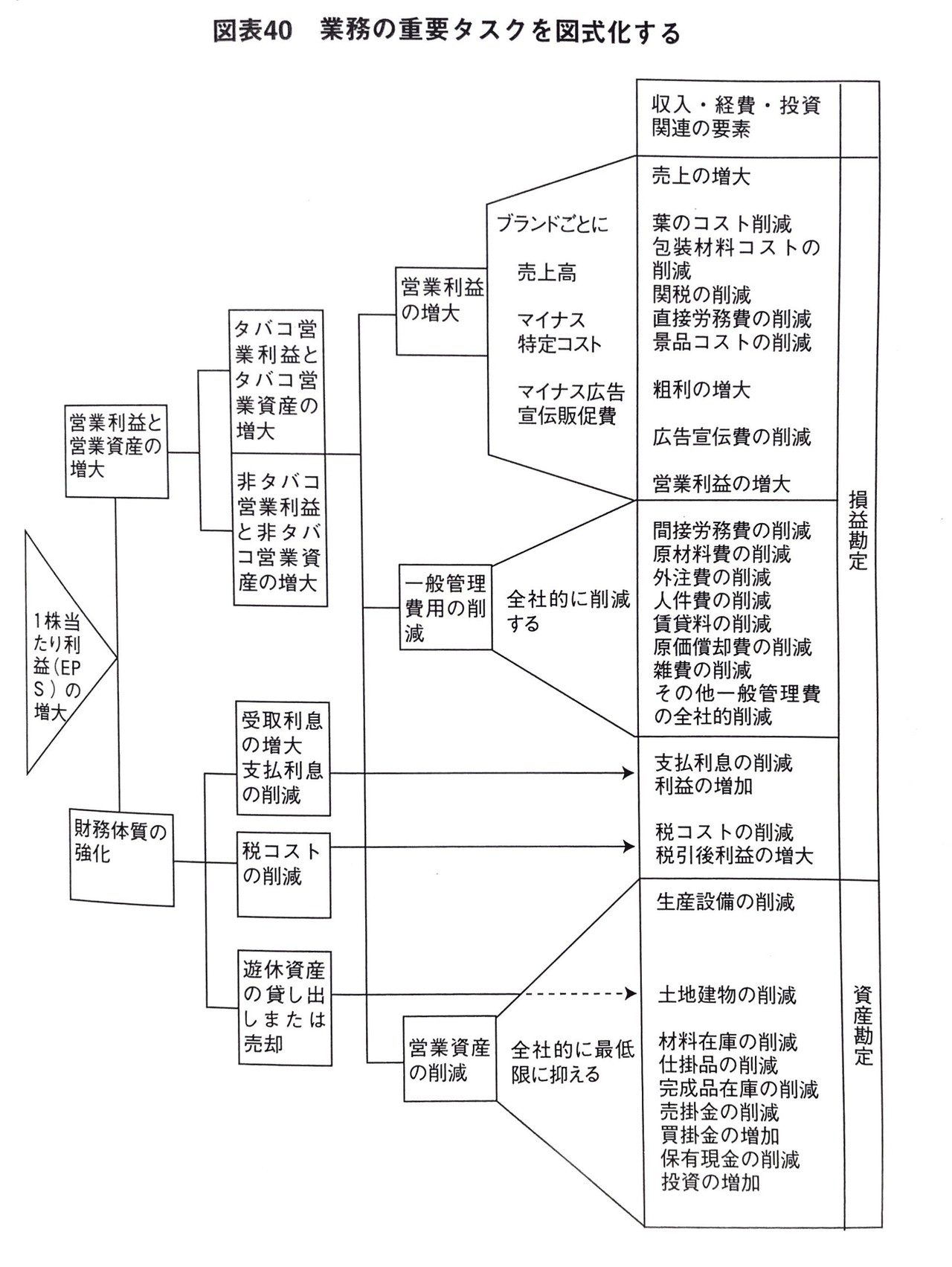
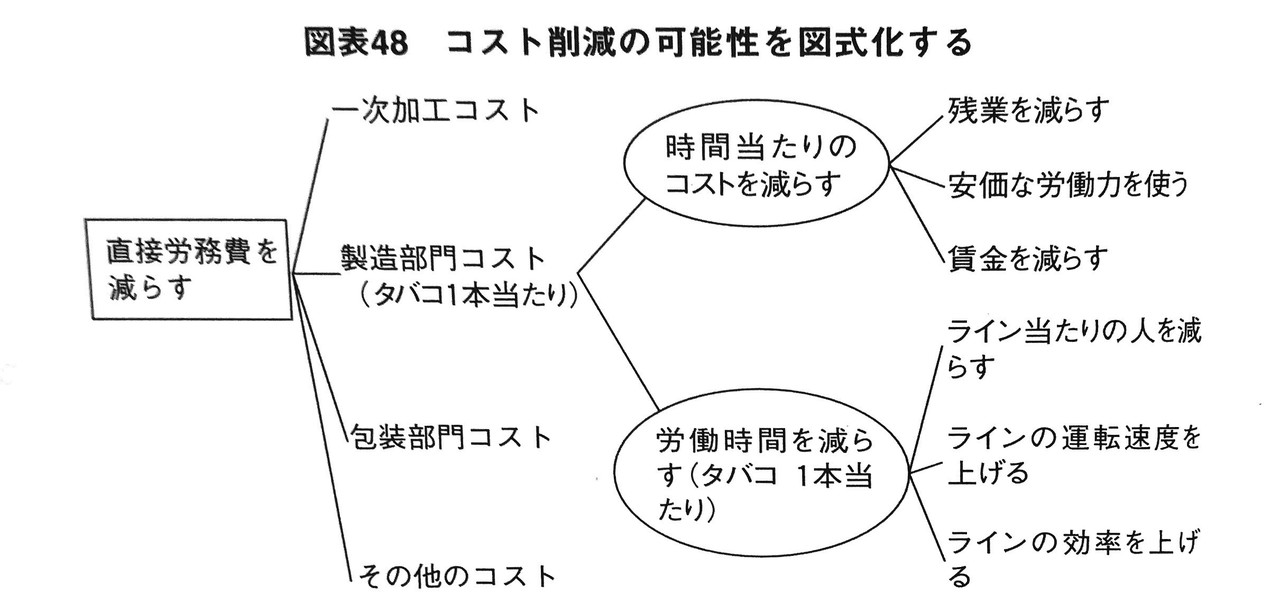
1枚目の図において、直接労務費を減らすことが論点に決定されたとしましょう。つまり、直接労務費が解決策を与えるべき真の問題だということです。
2枚目では、論点をロジックツリーの最上部ポイントに配置しています。その論点に対して、考えられる解決策をリストアップしてツリー状に図式化しています。
ただし、ロジックツリーの1段目は解決策を表すものではなく、直接労務費を要素分解したものです。これは、大論点を中論点や小論点に分解したものだと捉えればわかりやすいでしょう。
目標達成においても、ゴールをサブゴールに分解しますよね。例えば、東大合格をゴールとしたら、サブゴールは「模試で偏差値○○を取る」「この問題集を○月までに終わらせる」などになります。
ロジックツリーもそれと同じです。大論点(=直接労務費を減らす)を要素分解して、中論点や小論点にブレークダウンします。そのあとに解決策を述べていきます。
上の図では、タバコ一本あたりのコストを、
コスト/時間 × 時間/タバコ =コスト/タバコ
に分解しています。つまり、1時間あたりのコスト×タバコ一本当たりの時間数です。
その後、それぞれを削減するための解決策をいくつか提示していきます。
このロジックツリーはイシューツリーと似たようなものですね。
●フェーズ5 問題に対して何をすべきか?
フェーズ4で解決策が出揃ったら、次にそれらを絞り込んで実行すべき解決策を定めます。解決策を絞り込むには、それぞれの利点やリスクを評価します。
本に書いてあることはこれだけですね。フェーズ4までの段階で問題解決の90%くらいは完了しているので、このフェーズでは取り立てて学ぶことがないのかもしれません。
ですが、個人的にオススメの絞り込み方があります。それは以下の通りです。
①資源(時間やお金、人材など)的に実行可能か
②実行可能として、効果がどれくらい見込めるか(つまりインパクトがどれだけ大きいか)
この順で絞り込んでいきましょう。実行可能ではない解決策は、真っ先に消去します。次に、インパクトによる絞り込みを行います。実行可能な選択肢の中で、インパクトが最も大きいものが望ましいですね。
●おまけ
書籍の第9章では、「課題分析を実践する」という題名の見出しがありました。これについても解説しておきましょう。下の画像の内容を解説します。



部分ごとに分けて解説します。
1枚目(「歴史」より上):これは解説不要ですね。issueについては、既にフェーズ1で解説しました。
1枚目の「私の知る限り」〜2枚目の「恐れがある時」:「課題分析=複雑な状況下での意思決定分析のために開発されたテクニック」と定義されてますね。基本的に、筆者のイイタイコトはそれだけです。で、この定義の言い換え表現を整理すると、
①複雑な状況下での=以下のような状況下で=5つの箇条書きで示されている状況
②意思決定分析=自分の選択肢を明らかにすること、意思決定の合理的裏付けをもたらすこと
ですね。わかりやすく言えば、「課題分析=複雑な状況下において合理的な根拠を持って決断・行動するためのテクニック」という程度の意味でしょう。
2枚目の「たとえば」〜「開発されました」:課題分析の具体例として、ニューヨークで中間所得者層向けの住宅建設を計画する場合の話を挙げていますね。この段落では、状況の複雑さについて言及されています。たとえば、多くの選択肢が存在すること(箇条書きの2つ目)や、どのような決定をしようが他の政策分野の方針との間に何らかの問題が生じること(箇条書きの5つ目)です。
2枚目の「課題分析プロセスで」〜3枚目の「ならないことになります」:2枚目の段落では、課題分析の最も重要なステップについて説明されています。ステップごとに整理しましょう。
STEP1:方針分野の時系列チャートを作る
STEP2:それぞれのステージごとに、主たる意思決定要素(MDV)を明らかにする
STEP3:いくつかの仮説を設定し、その仮説に対してMDVと目的達成の影響関連性を記述する
STEP4:目的達成との関連性が極めて重要と判断したMDVの観点に基づいて最終の意思決定をする
このステップの例として、3枚目の画像が与えられています。この画像について解説しますね。
まずはSTEP1。方針分野=中間所得者層向け住宅建設の時系列チャートになっていることを確認して下さい。
次にSTEP2。それぞれのステージごとに、MDVが▶︎で明らかにされていることを確認して下さい。▶︎はいずれも、それぞれの意思決定に影響を与える「主な」要素です。箇条書きも恐らく意思決定に影響を与える要素だとは思いますが、影響度合いが低く見過ごしても良いようなもの、つまり「主なものではないもの」を箇条書きで表しているのでしょう。
次にSTEP3。「MDVと目的達成の影響関連性」は図で明記されていませんが、MDVが与える目的に対するインパクト(効果、影響度合い)を記述するということでしょう。3枚目の段落を見ると、MDVの一例としてテナント選定方針が挙げられています。テナント選定方針は重大なMDVであるということですね。
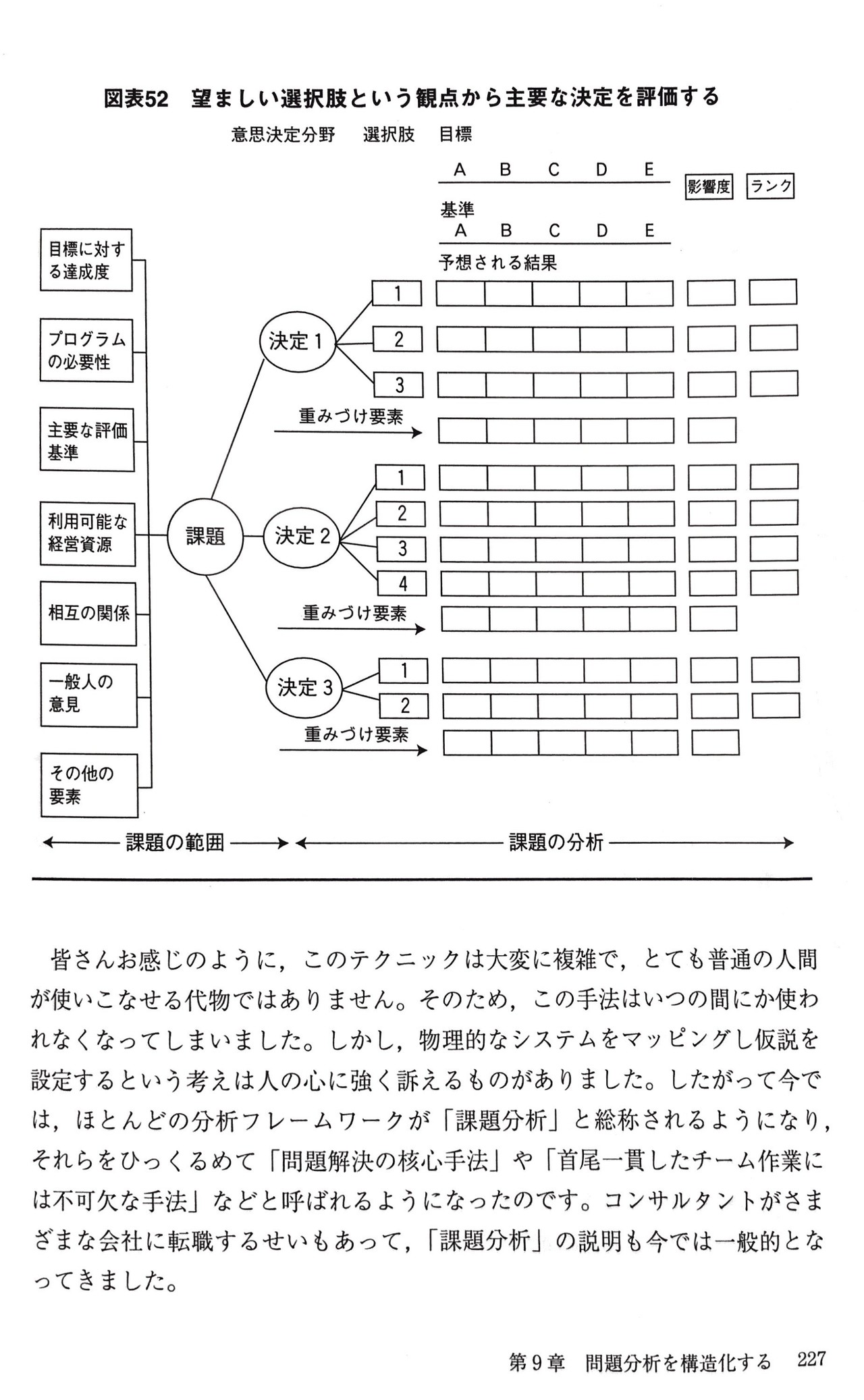
最後にSTEP4です。「目的達成との関連性が極めて重要と判断したMDVの観点に基づいて最終の意思決定を判断する=テナント選定方針の観点に基づいて最終の意思決定を判断する」ですね。そして、「最終の意思決定を判断する」ために、図表52を用います。図表52は書籍で説明がほとんどないので省略します。
全体の流れを整理すると、課題(issue)の定義→課題分析の定義→課題分析の具体例(複雑な状況の例+課題分析を実践する上で最も重要なステップ)
という流れですね。
【追補A 後半】
追補Aでは、「構造なき状況下での問題解決」が章タイトルになっていました。これはどういうことかと言うと、これまでの問題解決の方法では構造化(=図式化)できることが前提となっていましたが、問題の中には構造化ができないものがあるということです。発明を行う時はまさにその典型ですね。まあ構造があろうとなかろうと、用いるべき推論パターンは変わりません。アブダクションです。アブダクションでは、結果→ルール→ケースの順序で推論するのでした。
ではまず最初に、この章で使われる言葉の説明をしておきましょう。
分析的問題解決:第8章と第9章で用いられた問題解決パターン。結果とルール(=構造)の2つが存在するので、そこからケースを導くだけ。
科学的問題解決:分析的問題解決とは異なり、結果しか存在せず、ルール(構造)とケースが未知。
科学的問題解決ではルール(=構造)が存在しませんから、ルールを仮説設定する必要があります。つまり、「このような構造が考えられるだろう」ということを仮説的に設定します。この時、仮説を検証可能なものとするために、仮説をYes/No疑問文で表現します。
次に、仮説を排除するための実験、つまり検証方法を考案します。
その次に、検証を実行します。
最後に、仮説を追加したり変更しながら、検証の手続きを繰り返して結論を導きます。
具体例は下図を参照してください。

結果は、現実に起こった出来事です。この例では、「大砲を弾で撃てば、力が止まった後でも弾は飛んでいく」です。
ルールは、世の中のものが形作られるその方法についての考えです。つまり、結果を引き起こす構造です。科学的問題解決では結果を引き起こす構造が分からないので、ルール(=構造)を仮説的に設定します。
ケースは、個々の具体的な事例です。この図では、検証のことを指しています。
何だか仰々しいですが、分析的問題解決と科学的問題解決はどちらも推論パターンがアブダクションなので、方法に大して違いはありません。

一つずつ解説します。
フェーズ1では、理論上得られる結果(=R2)と現実に得られた結果(=R1)との不一致(=ギャップ)があるかどうかを明らかにします。
フェーズ2では、その不一致(=ギャップ)の原因となっている既存理論上の仮定を述べます(=既存理論をもとにして原因の仮説を立てる)。分析的問題解決と混同しやすいので整理しましょう。
分析的問題解決→結果を引き起こしてる、現状を構成する要素を図に書く→R1を引き起こしている状況(スタートポイント/オープニング+懸念される出来事)を述べる。つまり、R1を引き起こしてるルール(=世の中のものが形づくられるその方法についての考え)を、既知の情報をもとにして仮説的に述べる
科学的問題解決→その不一致の原因となる既存理論上の仮定を述べる→R2-R1を引き起こしているルールを、既存理論をもとにして仮説的に述べる。
ほぼ同じですね。2つの違いは、分析的問題解決ではルールが存在するが、科学的問題解決ではルールが存在しないということです。
フェーズ3では、不一致を排除して結果を説明できると考えられる代替仮説を述べます。つまり、R1(=現実に得られた結果)を生み出す原因の仮説を述べます。「こういう理由でR1が起きたのでは?」ということです。分析的問題解決でも、フェーズ3はR1を引き起こした要因の分析でしたね。
フェーズ4では、仮説の検証をします。検証を繰り返すことによって誤った仮説を消去していき、正しい仮説を絞り込んでいきます。これは、分析的問題解決では、フェーズ3の検証に該当する内容です。
フェーズ5では、文字通り検証結果に基づいて理論を再構築します。
以上ですが、ほぼ同じですね。2つの違いは、ルールが存在するかどうかと、解決策を述べるかどうかですね。科学的問題解決では解決策を述べる必要がないので、実質的には分析的問題解決のフェーズ3までの内容で済みます。
で、大事なことはこの「科学的問題解決」をいつ使うかなんですが、これは構造がない問題であれば適用可能です。構造がない問題って沢山あるんですよね。特に、種々の発明(アプリ、商品、サービスなど)が当てはまりますね。要するに、創造的な問題のことです。
また、今ビルゲイツが取り組んでいるような貧困問題の解決等の地球規模の複雑な問題であっても、科学的問題解決の方法論が適用可能かと思われます(これはただの仮説です)。まあ問題と名が付くものであればなんでも、解説noteの方法と補足noteの方法が適用可能でしょう。